What is Apache Hadoop?
The Apache Hadoop is the Big data tool and a software framework that is used to process large data sets across a cluster of computers. It uses a basic programming model called Map-Reduce. Hadoop can easily scale up and down from one server to thousands of servers; every server has its computation and storage area. The library of Hadoop is designed in such a way that it can handle failures at the application level and deliver high performance over a cluster of nodes.
Doug Cutting created Hadoop, and Yahoo delivered Hadoop to Apache Foundation in 2008. Multiple companies are providing Hadoop support such as IBM Biginsight, Cloudera, MapR, and Hortonworks.
The following figure represents the Hadoop Cluster.

Why Hadoop was discovered?
Let’s understand the reason behind the Hadoop invention.
1. High-Speed Data Generation
Now a day’s data is generating at a very high speed and traditional systems are failed to process such huge data in seconds. So to handle such high-velocity data there is a requirement of a system that can handle such data.
2. Large Dataset storage issue
Tradition RDBMS systems are not capable to handle such a huge amount of data and the addition of a new storage system in existing RDBMS is high.
3. Different format of Data
Traditional RDBMS systems are capable of storing structured data that comes in structured format but in the real world, the challenge is to handle structure, unstructured, and semi-structured data.
Prerequisites to Learn Hadoop
Let’s understand the prerequisites to learn Hadoop.
1. Knowledge of basic Unix commands
Basic knowledge of UNIX command is a must, such as loading data in HDFS, creating directories, downloading data from the HDFS file system, and so on.
2. Basic Java Knowledge
To create a MapReduce program a basic understanding of Java is a must. There are other languages also supported such as C, Perl, and so on.
Hadoop also has a high level of abstraction tools like pig and hive which don’t require awareness of Java.
Core Components of Hadoop
Hadoop has three core components.
1. Hadoop Distributed File System(HDFS): This is the storage layer of Hadoop.
2. Map-Reduce: This is the data process layer of Hadoop.
3. YARN: This is the resource management layer of Hadoop.
Let us understand each component of Hadoop.
1. HDFS
HDFS is the file system of Apache Hadoop. It is used to store a large number of files on the commodity of Hardware. It provides features such as fault tolerance, cost-effectiveness, scalability, high throughput, and so on. HDFS is developed to store less number of large files. It also supports hierarchical file storage.
The following figure shows the HDFS Architect (Master - Salves).
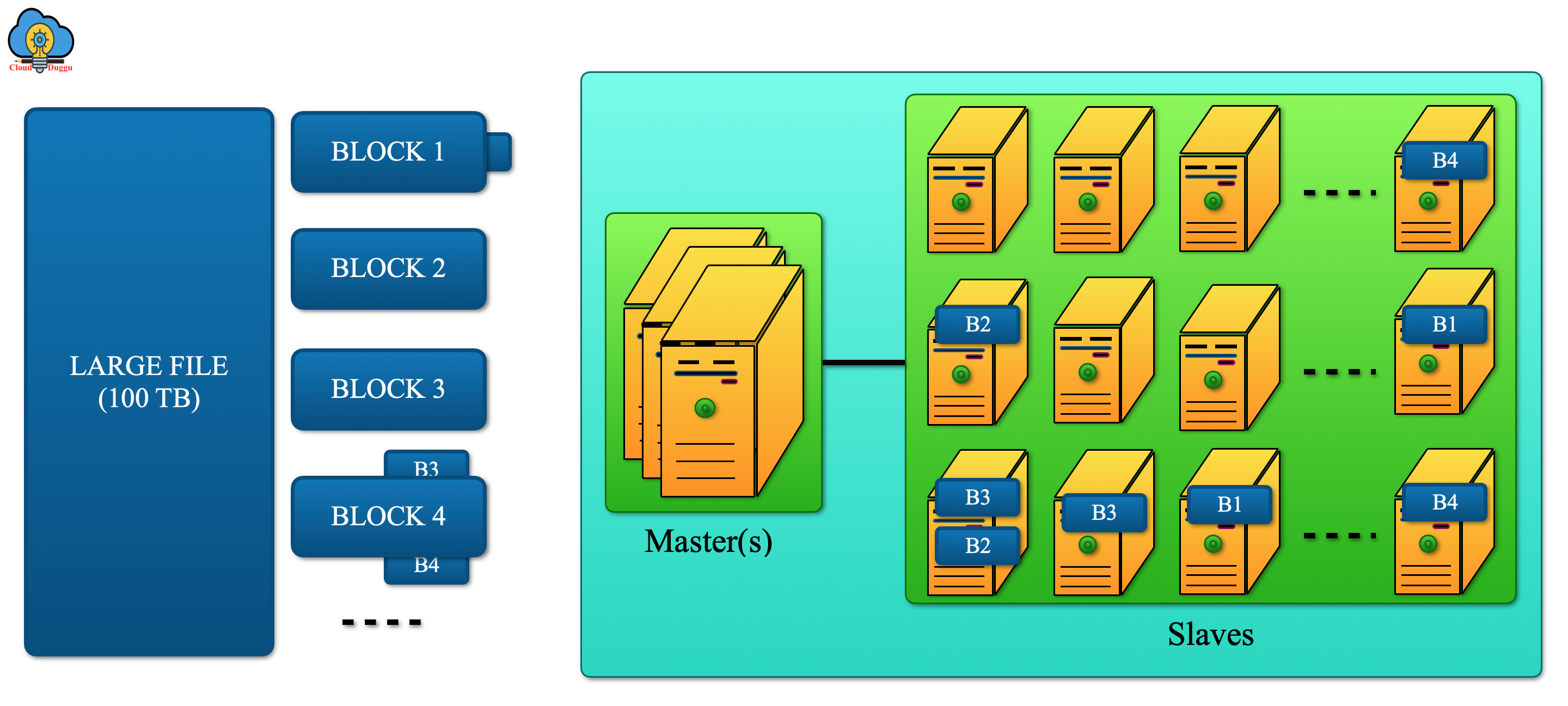
HDFS has two processes running on the master and slave nodes.
NameNode: Name node performs the below tasks.
- Namenode always runs on the master machine.
- Namenode is responsible for monitoring and managing all Datanodes present in the cluster.
- Namenode stores details of files like their location, permission, etc.
- Namenode receives a heartbeat single from all data nodes that are the indication that all databases are alive and working fine.
- Namenode maintains all changes done to metadata like deletion, creation, and renaming in edit logs.
DataNode: Data node performs the below tasks.
- Datanode always runs on the slave machine.
- Datanode is used to store user’s data and perform an operation such as new block creation, existing blocks deletion, and so on.
- Datanode processes all requests received from the user.
- Datanode sends a heartbeat to the name node every 3 seconds.
2. MapReduce
Map-reduce is the data processing layer of Hadoop, it is a software structure for easily writing applications that process huge volumes of data (terabytes of data) in-parallel on the Hadoop cluster that is very stable and fault-tolerant.
Map-Reduce process data in the following two phases.
Map: In this phase user’s data is converted into a pair of Key and Value based on the business logic.
Reduce: The Reduce phase takes input as the output generated by the map phase and applies aggregation based on the key-value pair.
3. YARN
YARN (Yet Another Resource Negotiator) is the resource management of Hadoop. It is job scheduling and resource management technology in the open-source Hadoop distributed processing framework. YARN is used to handle the functionality of resource management and job scheduling/monitoring.
YARN has the following two components.
Resource Manager
Resource Manager handles the allocation of resources to process a request such as CPU, memory, and so on. It runs on the Master node of the Hadoop cluster and keeps a track of all node managers.
Node Manager
The Node manager handles the resource capacity of the Node manager. It runs on the Slave machines and monitors the resource usage of each container. It keeps sending a Heartbeat to the Resource manager to indicate that all salve machines are alive.