The objective of this tutorial is to provide a complete overview of Hadoop MapReduce with examples.
Apache Hadoop MapReduce Introduction
Apache MapReduce is a software framework that facilitates extensive scalability across hundreds or thousands of servers in a Hadoop cluster. It is the core component of the Apache Hadoop framework. It provides the functionality to process large data in parallel on a cluster of Apache Hadoop nodes. Hadoop MapReduce has two different tasks namely Map job and Reduce job. The Map job takes data and converts it into key and value pair. On the other hand, Reduce job takes Map job output as an input and combine those data into a set of tuples. As per the name of MapReduce, the reduce job will always execute after the execution of the Map job.
Hadoop MapReduce provides the following list of benefits to get valuable insights from Big Data.
Simple: A developer can write code in a choice of languages, including Java, C++, and Python.
Flexibility: It provides the facility to easily access different sources and different types of data.
Scalability: Based on Business logic, MapReduce can process petabytes of data stored in HDFS.
Speed: Hadoop provides fast processing of huge amounts of data with parallel processing and
little data movement.
Scalability: Based on Business logic, MapReduce can process petabytes of data stored in HDFS.
Speed: Hadoop provides fast processing of huge amounts of data with parallel processing and
little data movement.
Why MapReduce was Designed?
Hadoop MapReduce was invented to overcome the issues which traditional databases were facing. The architecture of the traditional system has one centralized server to store and process the data. The traditional system is not competent to handle a large amount of scalable data such as a data set of petabytes. It creates a bottleneck during the processing of such large data.
Google fixed this issue by introducing the MapReduce framework in which a task will be divided into multiple subtasks and send to the cluster for execution. Once the execution is completed the result are sent back to the user.
MapReduce Phases
MapReduce process data in two phases.
- Map
- Reduce
Let us see each phase in detail.
1. Map Phase
The Hadoop MapReduce framework initiates a map task to process input data that includes the below steps.
- It uses the InputFormat to fetch the input data locally and create input key-value pairs.
- After that, it applies the job-supplied map function to each key-value pair.
- Post this, the framework performs sorting and aggregation of the results locally.
- If the job includes a Combiner, then it runs the Combiner for further aggregation.
- The framework performs the sorting of results on the local file system and in memory.
- Communicates progress and status to the Task Tracker.
How Many Maps?
The total number of maps is decided by the total number of blocks for the input files. Per best practice, there should be 10 to 100 maps per node. If there is a data set of 10 TB and the block size is defined as 1298 MB in that case there would be 82,000 maps. The Maps are configured by using (Configuration. set(MRJobConfig.NUM_MAPS, int)) parameter.
2. Reduce Phase
The Reduce Phase takes the output of the Map phase as an input and performs the aggregation and then share the final result.
- It gets the job resources locally.
- After that, it starts the copy phase to bring local copies of all the selected map returns from the map worker nodes.
- After the completion of the copy phase, the sort phase is started to absorb the copied result in a single sorted set of (key, value-list) pairs.
- Once the sort phase is completed the reducer functions are applied on each key-value pair.
- Once all the above steps are performed then the final result is saved to the output address, such as HDFS.
How Many Reduces?
The formula to calculate the number of reduces is (1.75 or 0.95 * number of nodes * the number of maximum containers per node). If we take 0.95 then all reduce will launch instantly and start processing map phase output as the map finish. If we take 1.75 then the fastest reduces will finish their job and will start a second time to perform much better load balancing.
MapReduce Program Flow
The following figure displays each phase of the MapReduce program.

- Input Phase: This is the initial phase in which the record reader reads each record of the input file and sends the parsed data (in the form of key-value) to the mapper. The input source of data for the MapReduce framework is HDFS.
- Splitting: This phase is used to divide the large file into small files and transfer it to Mapper. The file size is decided by block size.
- Mapping: In this phase, map action will be performed based on the business logic defined. It will process key-value pairs and generate zero or more key-value pairs.
- Shuffling: In this phase, map grouped key-value pairs are downloaded on the local system. The individual key-value pairs are sorted by key and group in a large data list, after this data list groups the equivalent keys together pass them to the reducer.
- Reducing: In this phase, the Reducer will take the grouped key-value paired data as input and apply a Reducer function on it per business logic such as aggregate, filter, and so on, and after processing return zero or more key-value pair for the final step.
- Final Result: In this phase, the output formatter translates the final key-value pairs of reducer function and writes it on file using record reader and post this operation user will receive the result.
Data Locality
Data Locality represents the movement of computation closer to data rather than data to computation. In a data-parallel system, it is considered to be one of the important constituents. Mapreduce framework takes the advantage of data locality by processing application logic new data which in turn increases the performance of the overall Hadoop Cluster.
MapReduce Code Example
Let us understand MapReduce with this program in which we are calculating sales data based on product brand.
1. Problem Statement!
Calculate Total Sales Price & Total Sales Count from Sales Data According to Sales Brand.
Input Sales CSV Data:
| prices | currency | merchant | brand | dateAdded | dateUpdated | name |
|---|---|---|---|---|---|---|
| 224.99 | USD | Bestbuy.com | Samsung | 2018-05-28T23:46:50Z | 2018-06-13T20:10:22Z | Samsung - 850 PRO 512GB Internal SATA III Solid State Drive for Laptops |
| 499.99 | USD | Bestbuy.com | Samsung | 2017-07-25T02:16:29Z | 2018-06-13T19:36:03Z | Samsung - 50 Class (49.5" Diag.) - LED - 1080p - Smart - HDTV" |
| 399.99 | USD | Bestbuy.com | Samsung | 2017-07-25T02:16:29Z | 2018-06-13T19:36:03Z | Samsung - 50 Class (49.5" Diag.) - LED - 1080p - Smart - HDTV" |
| 499.99 | USD | Bestbuy.com | Samsung | 2017-07-25T02:16:29Z | 2018-06-13T19:36:03Z | Samsung - 50 Class (49.5" Diag.) - LED - 1080p - Smart - HDTV" |
| 39.99 | USD | Bestbuy.com | Lenovo | 2015-10-16T20:50:30Z | 2018-06-13T19:38:34Z | Lenovo - AC Adapter for Select Lenovo Yoga Laptops - Black |
| 22.99 | USD | Bestbuy.com | Lenovo | 2015-10-16T20:50:30Z | 2018-06-13T19:38:34Z | Lenovo - AC Adapter for Select Lenovo Yoga Laptops - Black |
| 27.99 | USD | Bestbuy.com | Lenovo | 2015-10-16T20:50:30Z | 2018-06-13T19:38:34Z | Lenovo - AC Adapter for Select Lenovo Yoga Laptops - Black |
Output Calculated Result Through MapReduce:
| Samsung | TotalPrice: 1624.96 | TotalCount: 4 |
| Lenovo | TotalPrice: 90.97 | TotalCount: 3 |
2. How To Implement Solution In MapReduce Code?
1. We have used JAVA to implement this solution.
2. You can use the Maven Build Tool to create a solution package (jar).
Folder View:
|- SalesDataAnalysis
|- |- src
|- |- |- main
|- |- |- |- java
|- |- |- |- |- com.sales
|- |- |- |- |- |- SalesDriver.java
|- |- |- |- |- |- SalesMapper.java
|- |- |- |- |- |- SalesReducer.java
|- |- pom.xml
1. SalesDriver.java
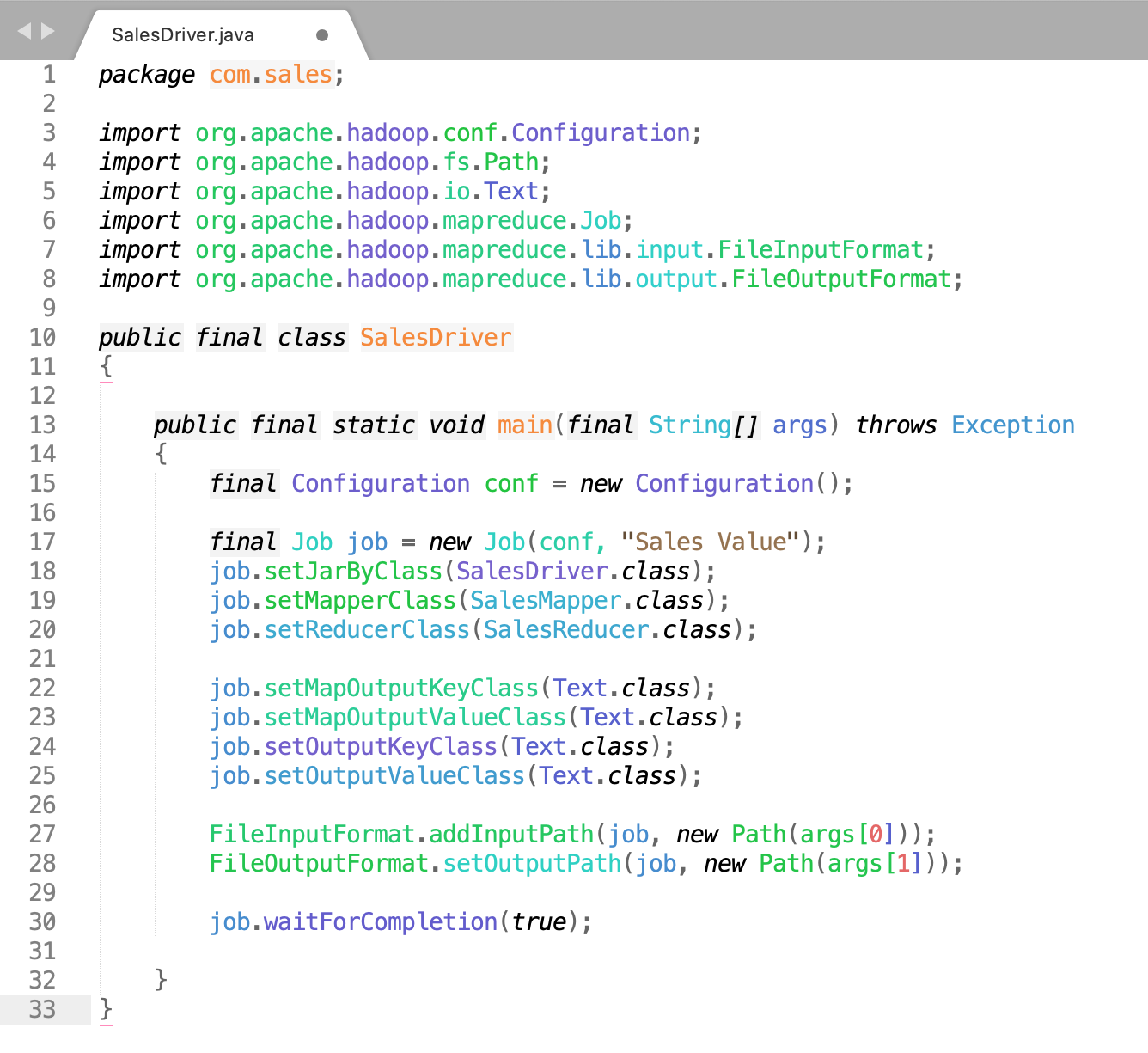
Click Here To Download "SalesDriver.java" Code File.
2. SalesMapper.java
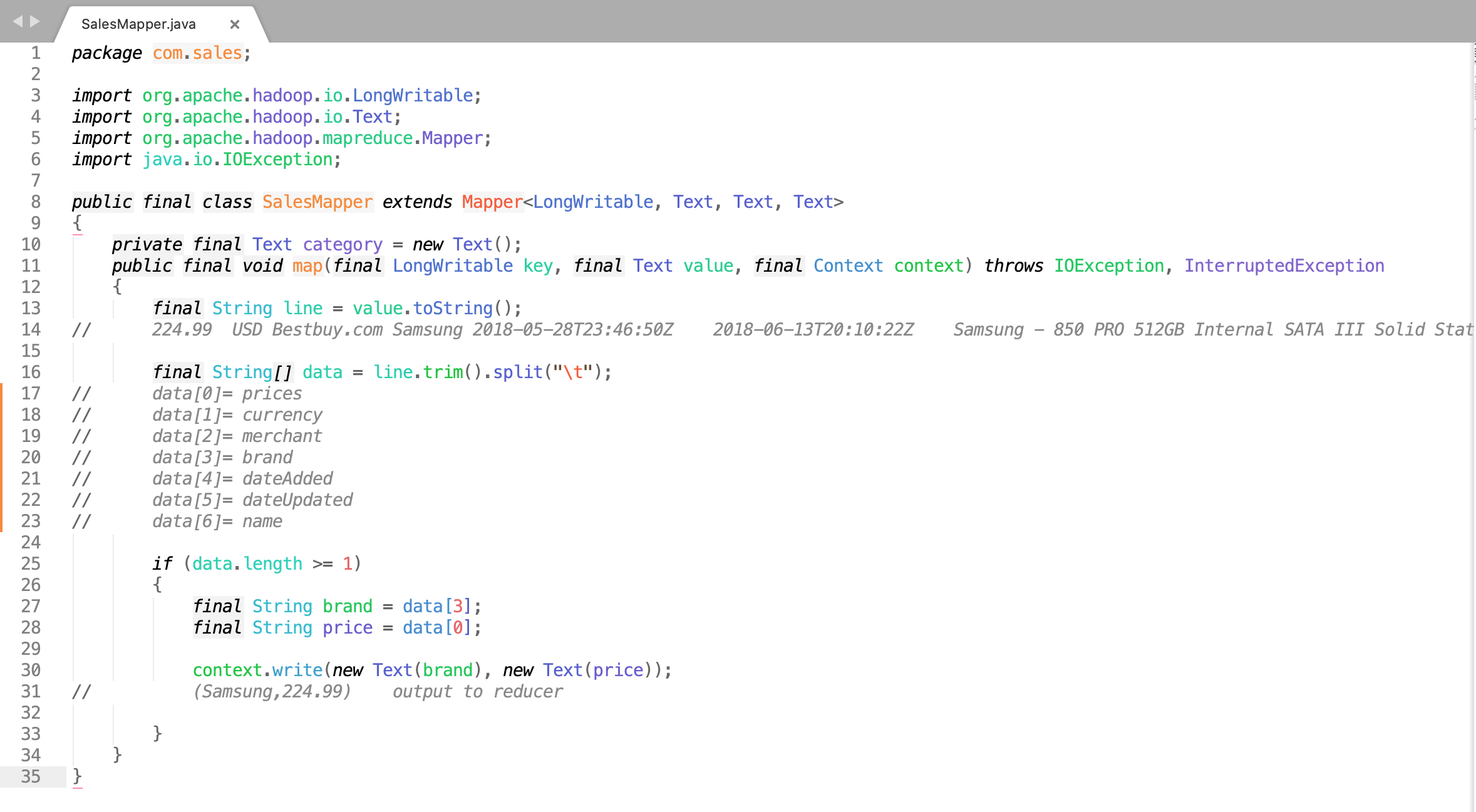
Click Here To Download "SalesMapper.java" Code File.
3. SalesReducer.java
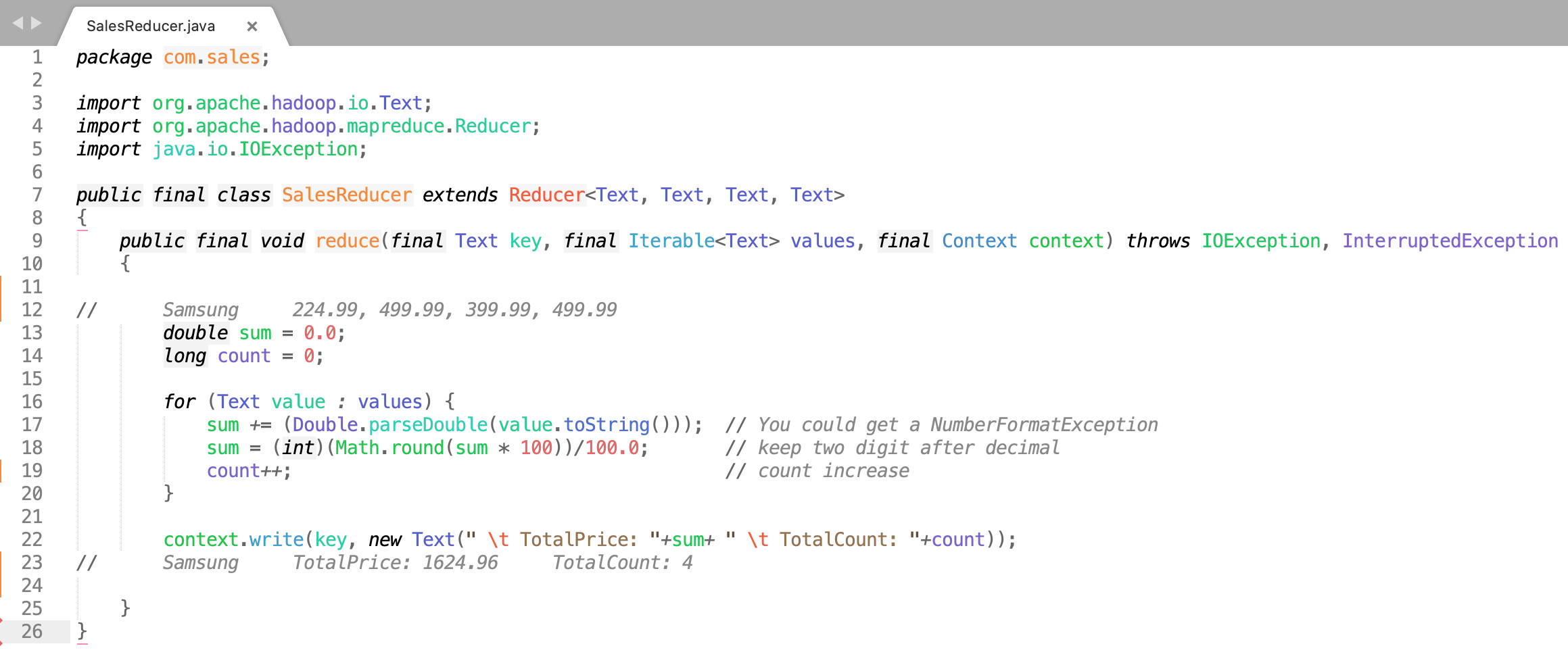
Click Here To Download "SalesReducer.java" Code File.
4. pom.xml

Click Here To Download "pom.xml" Code File.
3. How To Create a Solution Jar?
Maven must be installed in your system.
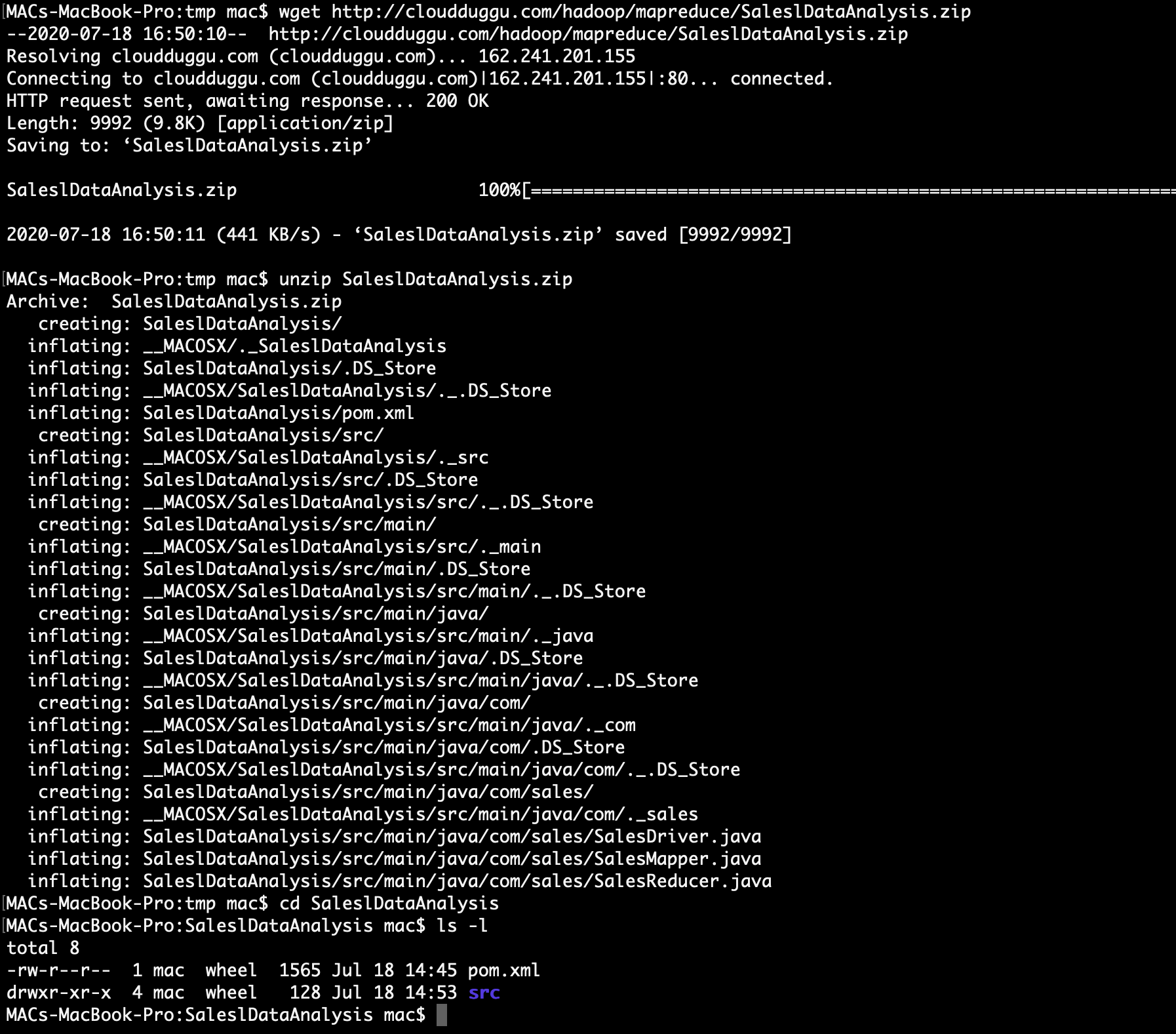
1. Download the project zip package and unzip it on your local system.
> wget http://cloudduggu.com/hadoop/mapreduce/SaleslDataAnalysis.zip
> unzip SaleslDataAnalysis.zip
2. Go inside the downloaded package and run the maven package command.
> cd SaleslDataAnalysis
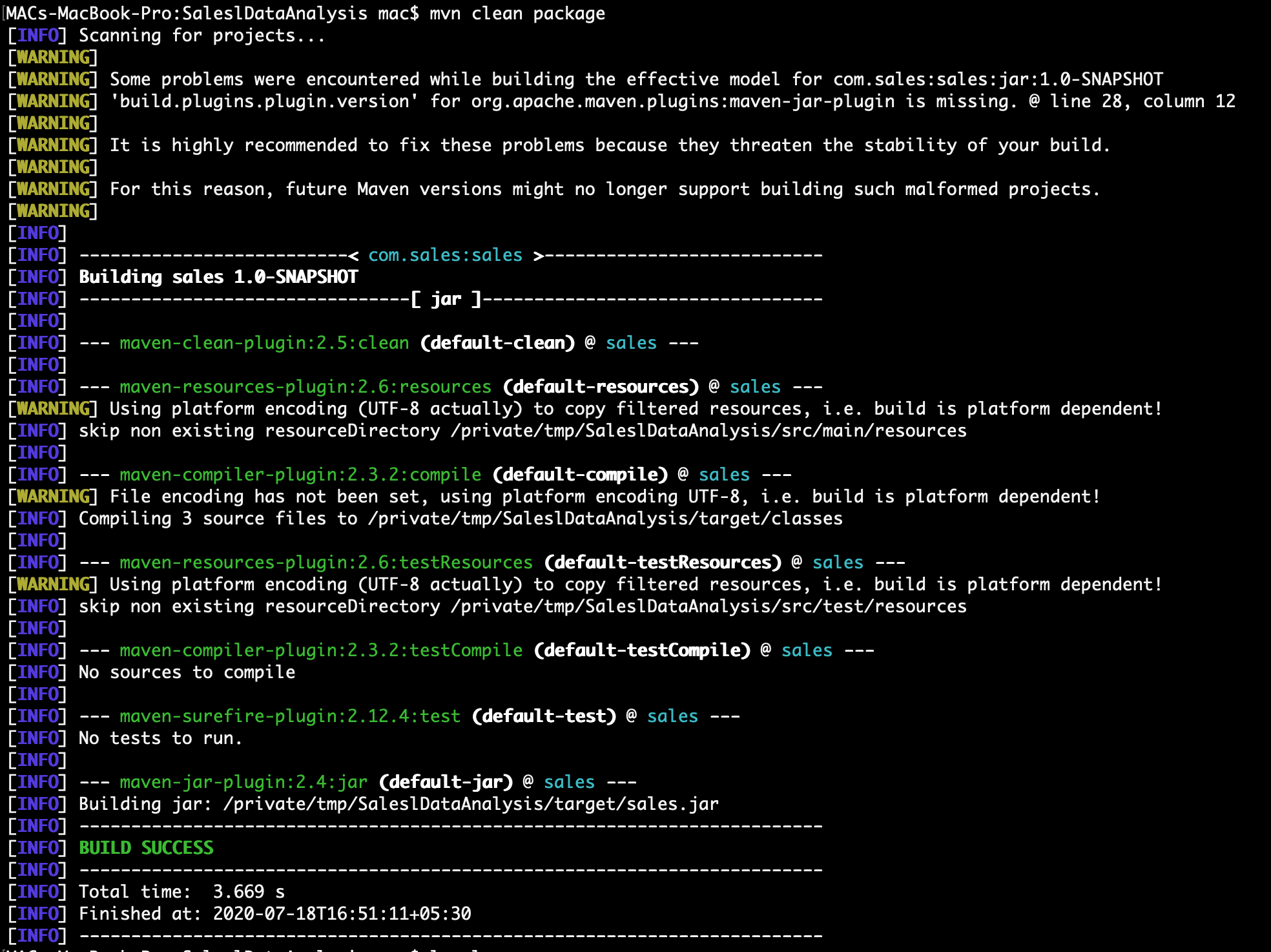
> mvn clean package
:) ...Now sales.jar is created in target folder (./SaleslDataAnalysis/target/sales.jar)
4. How To Run Solution Jar In Hadoop?
Download shell script file in which details are mention to run jar file.

Click Here To Download "sales_analysis.sh" shell script file.
1. Download the shell script file in Hadoop.
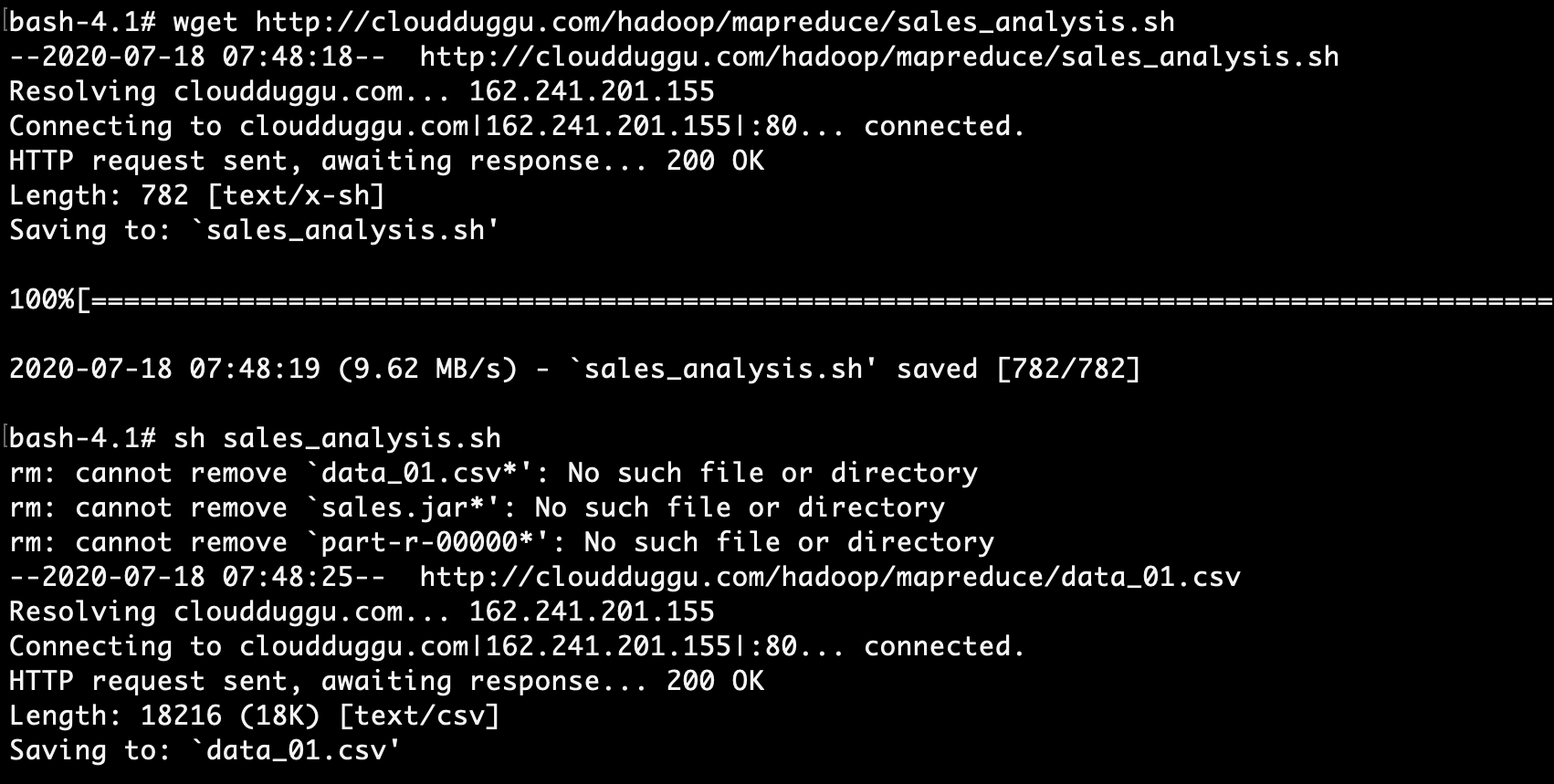
> wget http://cloudduggu.com/hadoop/mapreduce/sales_analysis.sh
2. Run the shell script file to get the result.
> sh sales_analysis.sh
...
...
...
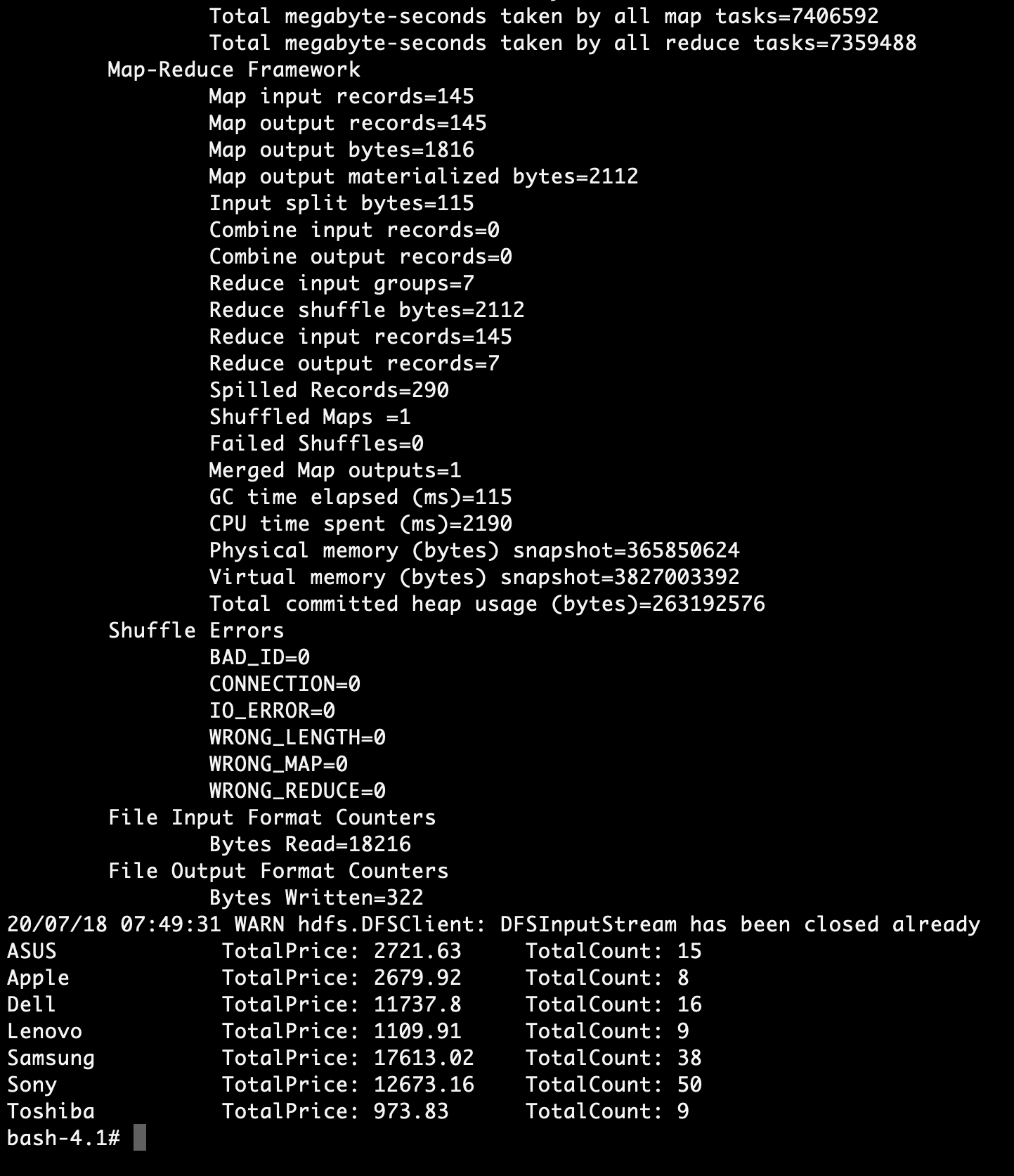
woo ... got the expected output.