In this tutorial, We will describe the steps to run a Word count program that is already present in the Apache Flink example directory. Before starting the program we will make sure that Apache Flume Cluster is up and running.
Apache Flink Word Count Program Execution Steps
Let's see the Apache Flink word count program execution with the following steps.
Step 1. Please verify if the Apache Flink cluster is up using the JPS command otherwise start the Flink cluster with the below command.
cloudduggu@ubuntu:~/flink$ ./bin/start-cluster.sh
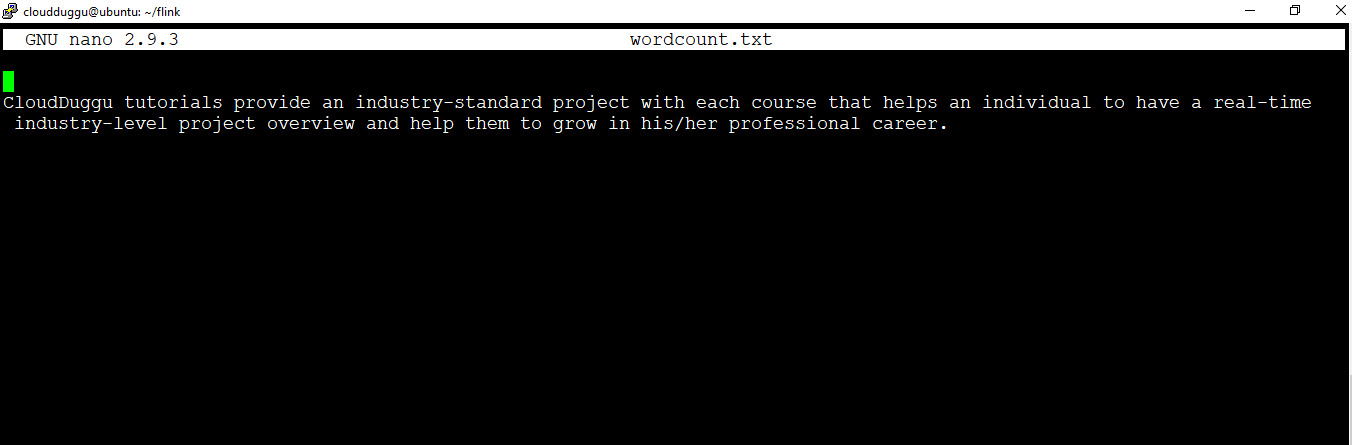
Step 2. Now we will create a .txt file named "wordcount.txt" under the flink home directory that will contain a paragraph of text using the below command.
cloudduggu@ubuntu:~/flink$ nano wordcount.txt

Step 3. After this go to the home directory of Flink and run the below command that will take "wordcount.txt" as an input file to count words and call the "WordCount.jar" file that is prebuilt with Apache Flink and located at "/home/cloudduggu/flink/examples/batch" path.
cloudduggu@ubuntu:~/flink$ bin/flink run examples/batch/WordCount.jar -input wordcount.txt -output /home/cloudduggu/flink/output.txt

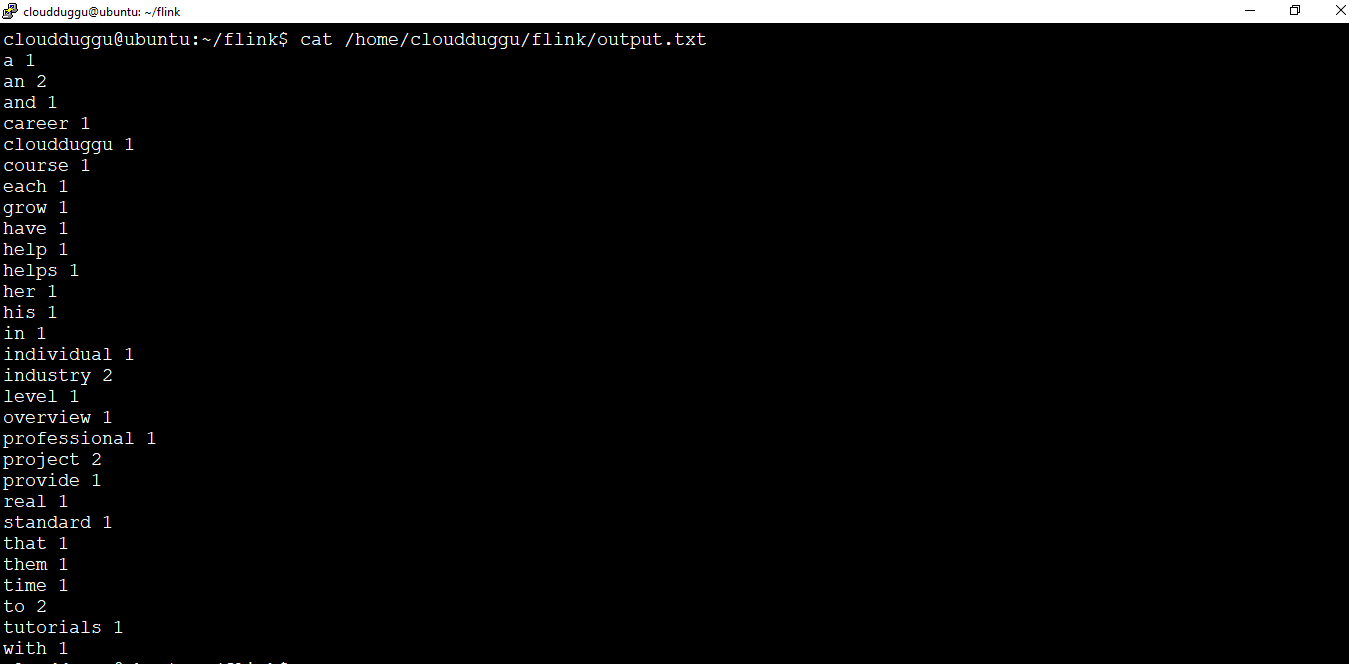
Step 4. Once the program is executed the output file is generated that was passed with --output parameter. In our case, the output file location was given at "/home/cloudduggu/flink/output.txt". Now we will open that file to check the word count of the paragraph.
cloudduggu@ubuntu:~/flink$ cat /home/cloudduggu/flink/output.txt
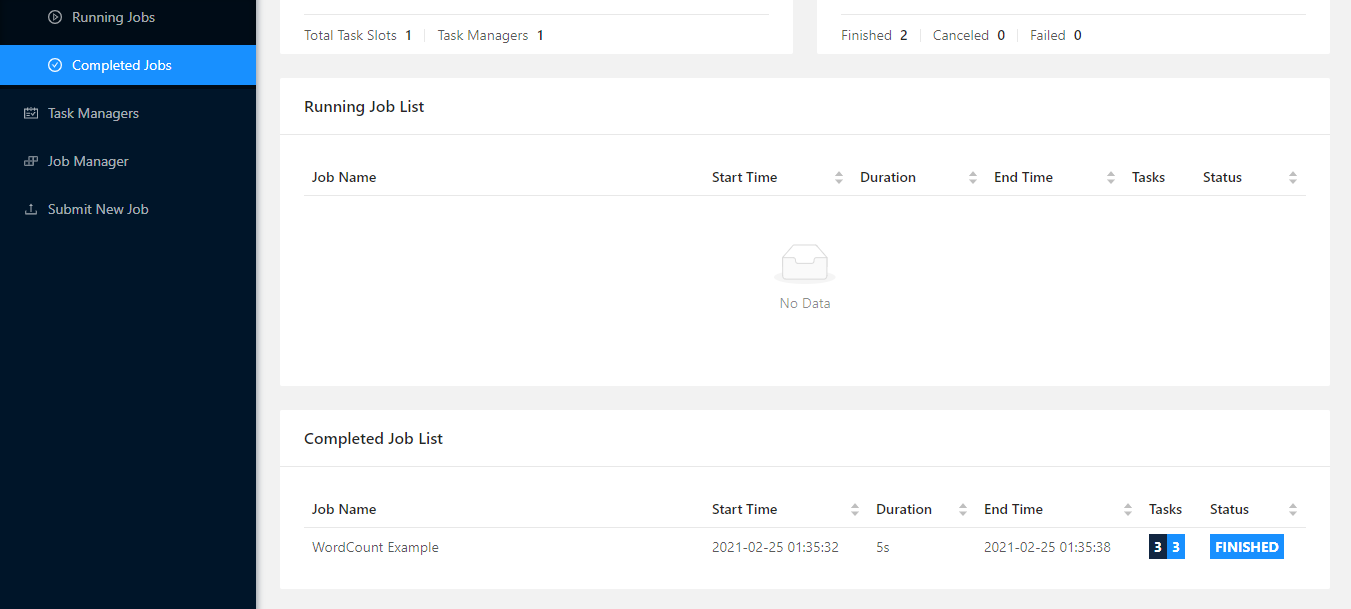
Step 5. We can use the Apache Flink Web console by opening it using "localhost:8081" and check the job status. We see from the following figure the job is finished.