Apache Hive Partitioning is a powerful functionality that allows tables to be subdivided into smaller pieces, enabling them to be managed and accessed at a finer level of granularity. It is a way of separating data into multiple parts based on a particular column such as gender, city, and date. The partition is identified by partition keys. Partitioning helps to improve the performance of query if we include partition column because by including Partition column query will fetch records of that Partition and ignore full table scan.
Apache Hive Partitions are used to reduce the load on Hadoop because as we know Hadoop HDFS stores data in the range of Terabytes to Petabytes and it is really difficult to query such a huge dataset as it requires heavy processing. To overcome this issue Hive offers partitioning. We can create partitions for larger tables so that only selective partition can be accessed when users submit the query.
Types of Partitioning
There are the following two types of Apache Hive Partitioning.
Let us see each Partition in detail.
1. Static Partitioning
Static partitioning is preferred when we load big files in Hive tables. It can be created for Hive Internal (Managed) table or External table. It inserts input data files individually into a partition table. Static Partition can be altered. To use Static Partition we should set property set hive. mapred.mode = strict in hive-site.xml configuration file.
Let us see the Static Partition with the below example.
To perform this example, we have created a table “USER_DATA” with DATE_DT and COUNTRY as Partition columns. We will load data into “USER_DATA”.
Create Table Syntax:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name data_type [column_constraint_specification] [COMMENT col_comment],
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)];
Create Table Statement:
CREATE TABLE USER_DATA (USER_ID INT
,USER_NAME STRING
,SITE_DATA STRING)
PARTITIONED BY (DATE_DT STRING,COUNTRY STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE
;
Command Output:

"User_Log.txt" Content:
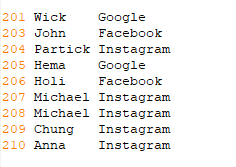
Load Table Statement:
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-29', COUNTRY='US');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-20', COUNTRY='UK');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-20', COUNTRY='UK');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-29', COUNTRY='UK');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-28', COUNTRY='INDIA');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-20', COUNTRY='RUSSIA');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-20', COUNTRY='RUSSIA');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-22', COUNTRY='NEPAL');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-22', COUNTRY='NEPAL');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-25', COUNTRY='INDIA');
Command Output:

[(col_name data_type [column_constraint_specification] [COMMENT col_comment],
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)];
,USER_NAME STRING
,SITE_DATA STRING)
PARTITIONED BY (DATE_DT STRING,COUNTRY STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE
;
Command Output:
"User_Log.txt" Content:
Load Table Statement:
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-29', COUNTRY='US');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-20', COUNTRY='UK');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-20', COUNTRY='UK');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-29', COUNTRY='UK');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-28', COUNTRY='INDIA');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-20', COUNTRY='RUSSIA');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-20', COUNTRY='RUSSIA');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-22', COUNTRY='NEPAL');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-22', COUNTRY='NEPAL');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-25', COUNTRY='INDIA');
Command Output:
Load Table Statement:
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-29', COUNTRY='US');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-20', COUNTRY='UK');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-20', COUNTRY='UK');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-29', COUNTRY='UK');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-28', COUNTRY='INDIA');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-20', COUNTRY='RUSSIA');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-20', COUNTRY='RUSSIA');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-22', COUNTRY='NEPAL');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-22', COUNTRY='NEPAL');
LOAD DATA LOCAL INPATH "/home/cloudduggu/hive/examples/files/User_Log.txt" OVERWRITE INTO TABLE USER_DATA PARTITION(DATE_DT='2016-05-25', COUNTRY='INDIA');
Command Output:
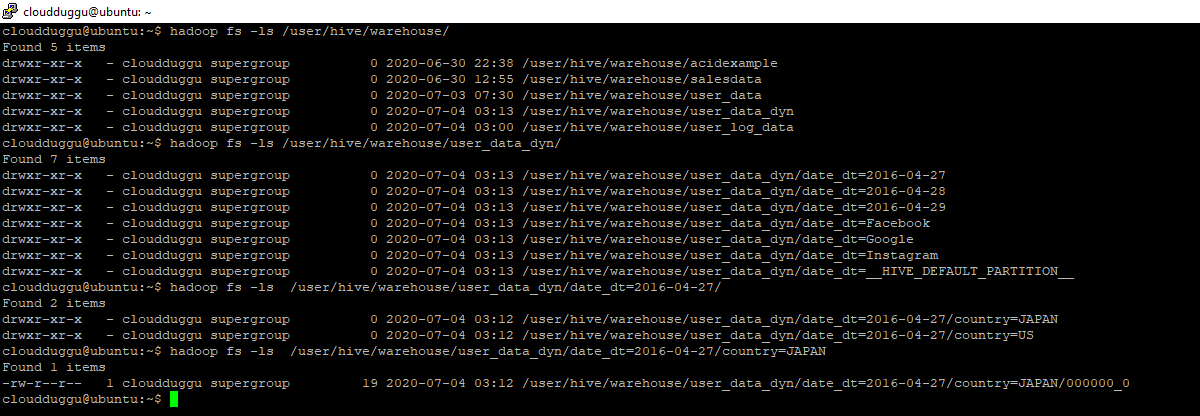
By default, this table is created as a Managed table and it will be stored at the default HDFS location “/user/hive/warehouse”. We can see from the below snapshot that Partitions are created and stored under the USER_DATA directory. We have created a partition on two columns DATE_DT and COUNTRY and the same we can see in the below snapshot.


Data loading in Apache Hive is a rapid process and it does not trigger a Map/Reduce job. That's the reason our file is stored as User_Log.txt instead of 00000_o file.

2. Dynamic Partitioning
Dynamic Partition is known for a single insert in the partition table. It loads data from the non-Partitioned table and takes more time than Static Partition. We can use Dynamic Partition when we have large data already stored in a table. It can be used in Hive in non-strict mode by setting this parameter Hive.exec.dynamic.partition.mode= nonstrict. Dynamic Partition can’t be altered.
Let us see Dynamic Partition with the below example.
To perform this example, we have created two tables “USER_DATA_DYN” and “USER_LOG_DATA”. Table “USER_DATA_DYN” will be a Partition table with column DATE_DT and COUNTRY as Partition column and table “USER_LOG_DATA” will be a non-Partition table. We will insert data in “USER_DATA_DYN” using the non-Partition table “USER_LOG_DATA”.
Create Table Syntax:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name data_type [column_constraint_specification] [COMMENT col_comment],
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)];
Create Table Statement:
[(col_name data_type [column_constraint_specification] [COMMENT col_comment],
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)];
Let us create the table “USER_DATA_DYN”.
,USER_NAME STRING
,SITE_DATA STRING
)
PARTITIONED BY (DATE_DT STRING,COUNTRY STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
Command Output:

Create Table Statement:
Let us create table "USER_LOG_DATA" and load data using the UserLogdata.txt file.
,USER_NAME STRING
,SITE_DATA STRING
,DATE_DT STRING
,COUNTRY STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
"UserLogdata.txt" Content:

Load Table Statement:
LOAD DATA LOCAL INPATH '/home/cloudduggu/hive/examples/files/UserLogdata.txt' OVERWRITE INTO TABLE USER_LOG_DATA;
Command Output:

Command Output:
Now we will load data in table “USER_DATA_DYN” using “USER_LOG_DATA”. We can see from the below snapshot that when we start to insert data into USER_DATA_DYN”, MapReduce jobs are started executing by the framework.
Load Table Statement:
SET hive.exec.dynamic.partition = true;
SET hive.exec.dynamic.partition.mode = nonstrict;
INSERT OVERWRITE TABLE USER_DATA_DYN
PARTITION(DATE_DT,COUNTRY)
SELECT USER_ID,USER_NAME,SITE_DATA,DATE_DT,COUNTRY FROM USER_LOG_DATA;
Command Output:

PARTITION(DATE_DT,COUNTRY)
SELECT USER_ID,USER_NAME,SITE_DATA,DATE_DT,COUNTRY FROM USER_LOG_DATA;
We can see that we didn’t load table multiple time to create multiple Partitions as it was the case in Static partitioning. In this example all Partitions are created in “USER_DATA_DYN” based on DATE_DT and COUNTRY column of “USER_LOG_DATA” also we can see out the file is created with 000000_0 and not with the name because MapReduce job was executed.
Advantage of Apache Hive Partitioning
- Using Apache Hive's partitioning the data is organized in various partitions.
- We a user will run a query on the Partition table using the partition column then only selected Partition data is fetched and not completed data set.
- With the help of Partitioning, the system resources such as the number of mappers, I/O operation, and response time for the query are decreased.