Apache Drill supports the ANSI standard of SQL to run queries on data sets. We can use SQL to run the query against data sources like HBase, Hive, distributed file system, local file system, RDBMS systems, non-relational databases, etc. Using the Drill special functions and operators we can drill down more on nested data.
Apache Drill supports the data definition statements to create the table, create the view, drop table, drop view, alter statement, describe table/views/database/workspace, and so on. In this section, we will go through the following Drill Data definition statements.
Drill CREATE TABLE AS (CTAS)
We can create a table in Drill using the create table as a statement. A table in Drill can be created in df.tmp workspace. It can't be created in HBase or Hive using the storage plugins and another thing is that the workspace should be set to writable using this parameter "writable": true.
Syntax:
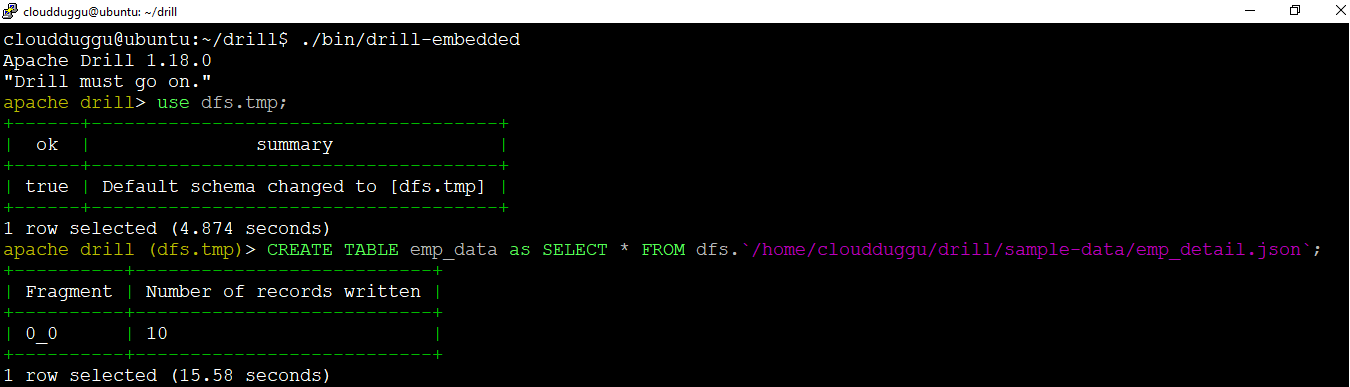
We will create a table in Drill based on the JSON dataset named "emp_detail.json" that we already created in the previous section. Go to the drill home directory and start the Drill in embedded mode after that set the schema to dfs.tmp and run the CREATE TABLE statement.
Command:
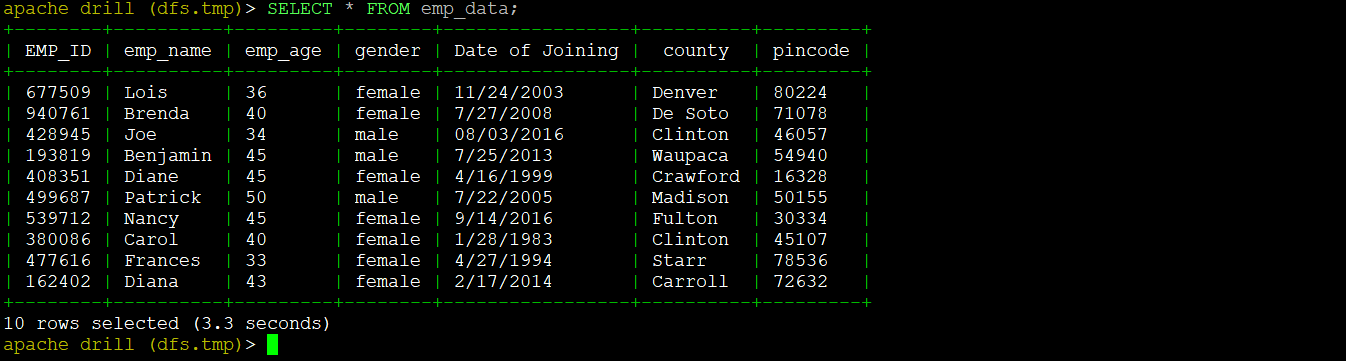
Output:
Drill CREATE TABLE PARTITION BY AS (CTAS)
We can create a Drill table using the PARTITION BY clause that will provide the best performance when the data is huge and the query will be fired based on the partition column.
Syntax:
[ PARTITION BY (column, . . .) ]
AS SELECT column_list FROM <source_name>;
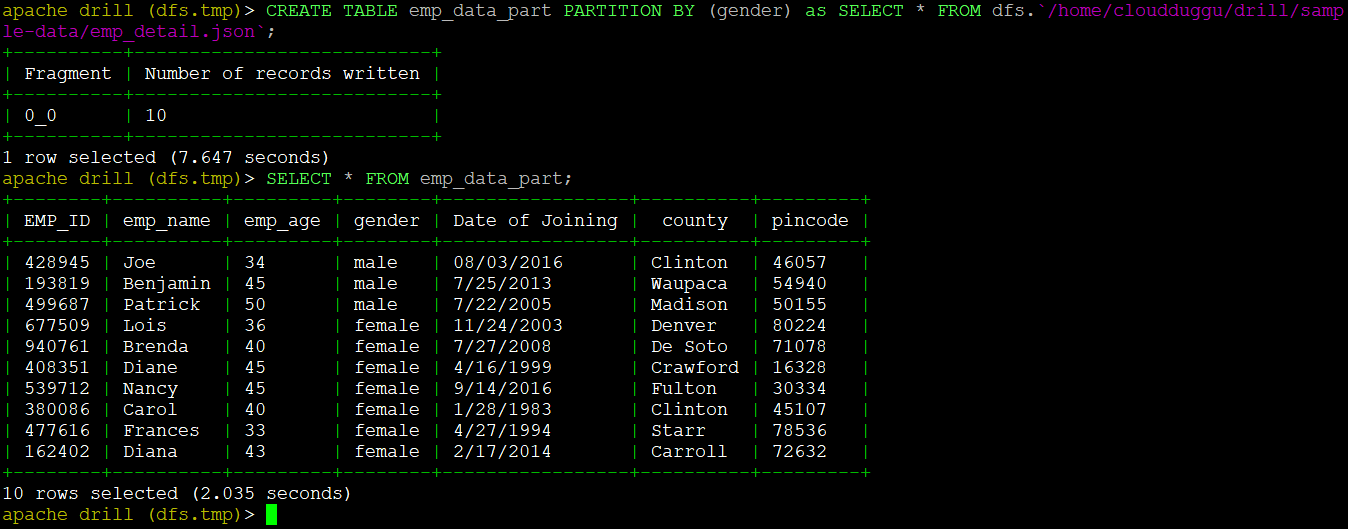
Now we will create a table named "emp_data_part" and partition this table by the "gender" column.
Command:
Output:
We can see the output of the query based on the PARTITION column gender.
Drill CREATE VIEW
A View is a logical representation of data and in Drill, we can create views combining multiple data sets that represent data from a single data source.
Syntax:
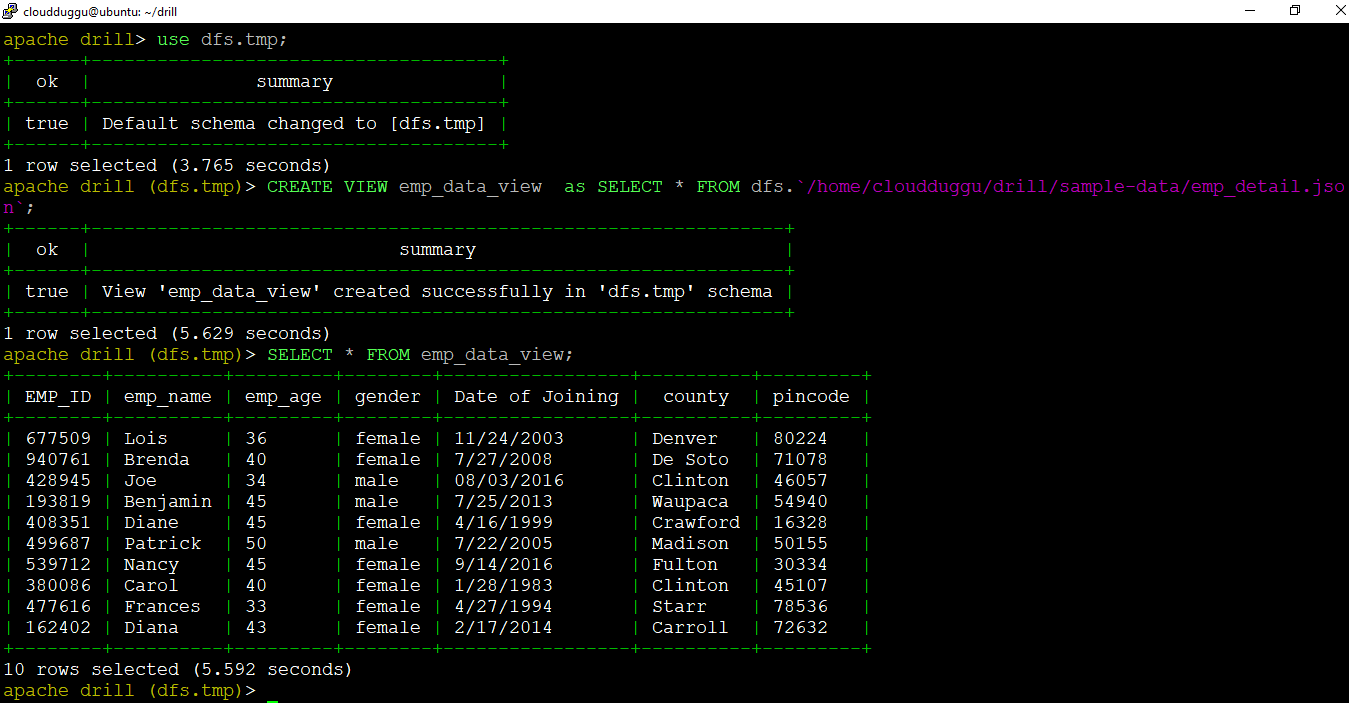
We will create a view named "emp_data_view" that will be based on the emp_detail.json data file.
Command:
Output:
Drill DROP TABLE
Drill DROP table is used to drop table from dfs storage plugin.
Syntax:
Let's drop the table "emp_data" that we have created in CREATE table section.
Command:
Output:

Drill DROP VIEW
Drill DROP view is used to drop view from Drill.
Syntax:
We will use the DROP VIEW command and drop the already created view name "emp_data_view".
Command:
Output:
