Apache HBase Data replication refers to copying data from one cluster to another cluster by replicating the writes when the first cluster receives it. In Apache HBase, Intercluster replication is achieved by log shipping asynchronously. Data replication is a disaster recovery solution and this can be implemented in Apache HBase.
The Apache HBase uses the mater push pattern to send the write-ahead log to the slave clusters. Each region server maintains its write-ahead log and sends the same to slave nodes.
Some use cases for cluster replication include.
- Backup and disaster recovery.
- Geographic data distribution.
- Data aggregation.
Replication Architecture Overview.
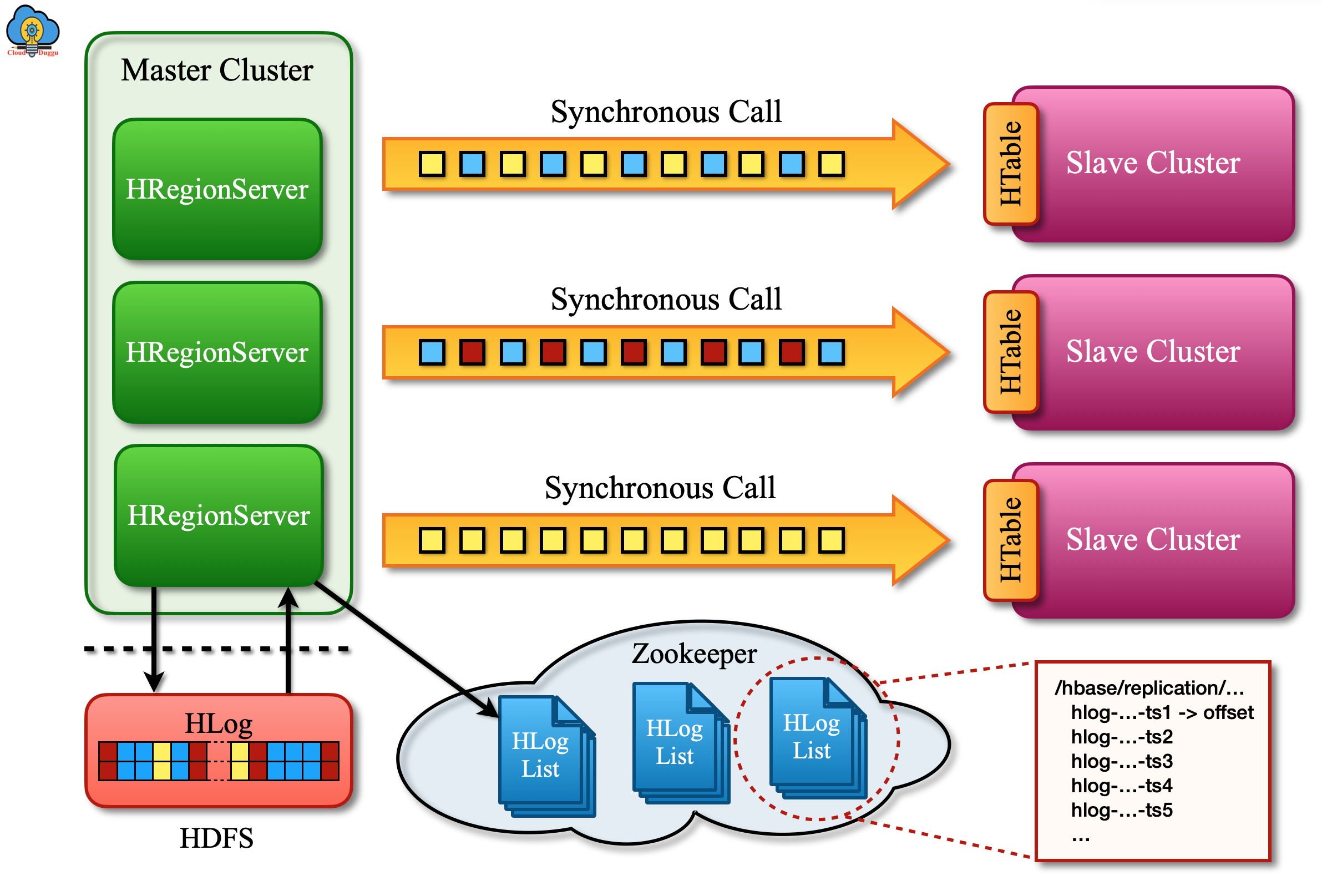
Life of a WAL Edit
Apache HBase WAL logs go through many steps which are mentioned with the following steps.
- Apache HBase data is modified using either PUT or DELETE operation.
- Now the Apache HBase region server writes the request to the WAL. In case of failure, it will be rewritten.
- If the modification cell is part of the replication column family then the edit log generated for the PUT or DELETE will go in queue for further replication.
- After that, as a part of the batch method, the edit will be scanned from the log.
- Now edit will be assigned a master UUID.
- Now edits will be read by the Apache HBase region server in sequential order and order in buffers for example a table is assigned one buffer.
- After that, the WAL that is going to replicate will be registered with ZooKeeper.
- In the initial three-step, the edit is inserted and define as unique.
- Now the Apache HBase Master will try the same process to send logs.
- In case the Slave region server is not available then the Master selects a sub-set of region server and tries to send logs.
- The WAL which are not able to deliver is stored in the ZooKeeper queue.
- Once the Slave node gets online the normal buffer applies process is started.