Apache Spark Cluster Mode Overview
Apache Spark is a cluster-computing framework on which applications can run as an independent set of processes. In Spark cluster configuration there are Master nodes and Worker Nodes and the role of Cluster Manager is to manage resources across nodes for better performance. A user creates a Spark context and connects the cluster manager based on the type of cluster manager is configured such as YARN, Mesos, and so on.
The following figure shows the Cluster manager coordination.
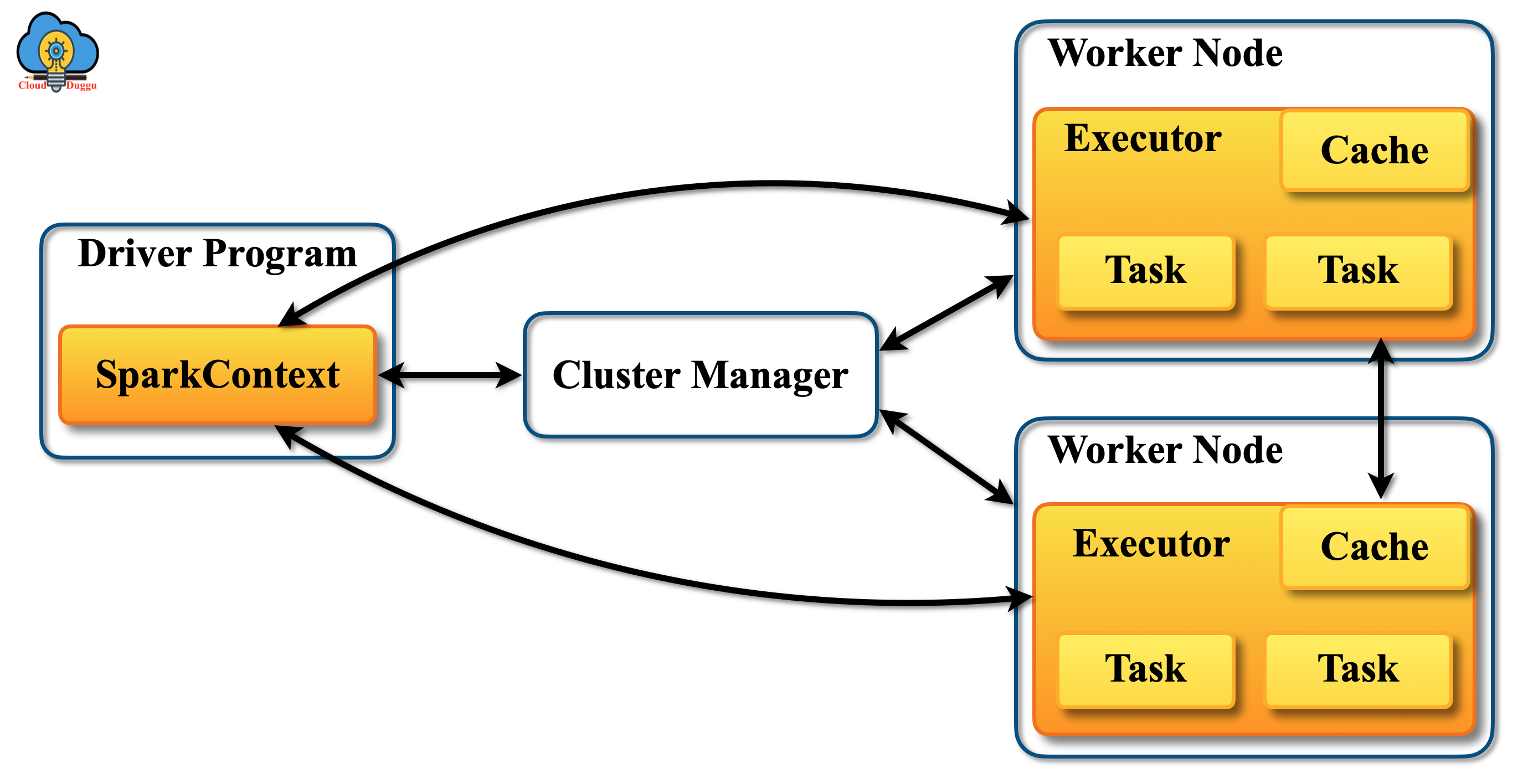
Let us see some important points about the Cluster manager.
- Apache Spark applications get their executor processes that run the various task and stay alert during the execution cycle.
- Apache Spark can easily run on other Cluster managers such as YARN, Mesos which supports other applications as well.
- Driver program continuously accepts the connection for executors during its continuance.
- Apache Spark driver program schedule the task on the cluster and run closure to the worker nodes. Spark Driver program should be on the same local area network.
Apache Spark system supports the following Cluster Managers.
Now let us see each Cluster Manager in the following section.
Apache Spark Standalone Cluster
Apache Spark Standalone configuration gives a standalone machine configuration that has a master node and worker node and can be used for testing purposes. We can start the Master node and worker nodes manually. For more detail, on Spark Standalone installation you can refer "Installation on Single Node" tutorial of Spark installation.
We can start the Apache Spark Master node using this command (./sbin/start-master.sh).
Once the Apache Spark Master node is started, then it will show the URL itself (spark://HOST: PORT UR) that we can use to connect with Spark worker nodes. We can also use(http://localhost:8080) for the Spark Master web interface. Apart from this, we can start the Spark worker node and make a connection with the Spark Master node using this command ($./sbin/start-slave.sh master-spark-URL.)
Apache Mesos
Apache Spark can work well on the cluster of nodes that are operated by the Apache Mesos. Apache Mesos cluster has the configuration of Mesos Master nodes and Mesos Agent nodes. Mesos Master handles the agent daemons which are running on nodes and Mesos frameworks are used to handle the task on agents.
The framework which runs on Apache Mesos has two components namely schedular and executor, the schedular is registered with the Master node and responsible to manage resources and the executer process is responsible to process framework tasks.
The following are the advantages of deploying Apache Spark on Apache Mesos.
- A dynamic partition is provided in between Apache Spark and other frameworks.
- A scalable partitioning is provided between various instances of Spark.
Apache Hadoop YARN
Apache Spark can be deployed on Hadoop YARN resource manager as well. When applications run on YARN in that case each Spark executor runs as a YARN container and MapReduce schedules a container and starts a JVM for each task. Spark achieves faster performance by hosting multiple tasks in the same container.
It has the following two modes.
- Cluster Deployment Mode
- Client Deployment Mode
1. Cluster Deployment Moder
In cluster deployment mode driver program will run on the Application master server. It is responsible for driving the application and requesting the resource from YARN.
2. Client Deployment Moder
In client deployment mode driver program will run on the host where a job is submitted and in this case ApplicationMaster will just present there to ask executor containers from YARN and then those containers start after that client communicates with them to schedule work.