What is Apache Spark ?
Apache Spark is an open-source fast-growing and general-purpose cluster computing tool. It provides a reach set of APIs in Java, Scala, Python, and R and an engine that supports general execution. It supports higher-level tools like Spark SQL for structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming for stream processing of live data and SparkR. Apache Spark is almost 100 times faster compared to the Hadoop MapReduce framework.
Apache Spark is written and developed in Scala functional programming language. Spark can be integrated with Hadoop to process existing data. Apache Spark application has a driver program that is responsible to run the user’s main function and execute multiple operations over a cluster of nodes. Spark basic abstraction is RDD which stands for the resilient distributed dataset. RDD is a collection of elements which are spread over a cluster of node and perform the parallel operation. RDD can be persisted in memory which can be reused efficiently for multiple operations. RDD is capable to recover itself in case of failure.
Apache Spark History
Let us see a year by year evaluation of Apache Spark.
2009: At UC Berkeley's AMPLab, Spark was invented by Matei Zaharia.
2010: Under the license of BSD, Spark was open-sourced.
2013: Spark was distributed to Apache Software Foundation and shifted its consent to Apache 2.0.
2014: Spark set a new world record in large scale sorting.
2015: Spark becomes one of the most active open source big data projects.
Apache Spark Components
Let us have a look at Apache Spark components which are Spark SQL, Spark Core, Spark MLlib, Spark Streaming, Spark GraphX, SparkR. All these components play an important role in resolving Big Data issues.
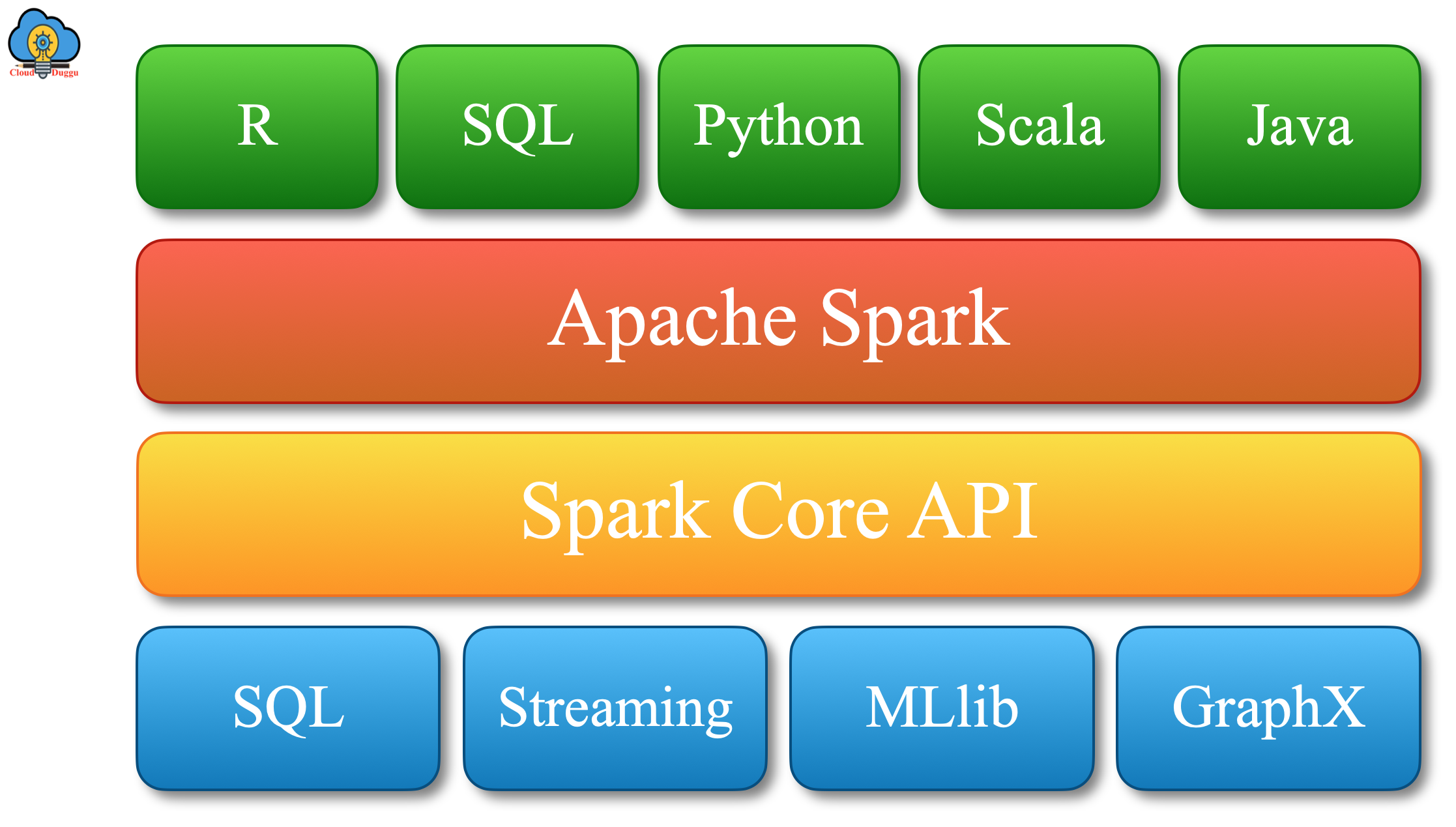
Let us have a look at the components of Apache Spark.
1. Spark Core
Apache Spark Core is the execution engine of Spark architecture. It is responsible to provide scheduling, distributed task dispatching, and I/O functionalities. It provides support for programming languages such as Scala, Java, and Python, and so on. It also provides support for non-JVM languages as well such as Julia.
2. Spark SQL
Apache Spark SQL element is used to process structured data and it is present on top of Spark core. Spark SQL uses DSL(Domain Specific Langauge) to operate on DataFrames. Spark SQL also supports SQL language through CLI(command-line interface) as well as through ODBC/JDBC drivers.
3. Spark Streaming
Apache Spark Streaming is another core API of Spark architecture that provides fault-tolerant, high-throughput, and scalable stream processing for live streaming data. It ingests data from various data sources such as Flume, Kafka, Kinesis as well as TCP sockets and performs high-level operations such as a map, reduce, join and after processing it push processed data to downstream such as database, filesystems or a live application dashboard.
4. MLlib
Apache Spark MLlib is a machine learning(ML) library that is used to make practical machine learning easy and scalable. MLlib provides nine times better performance compared to Apache Mahout.
Apache Spark MLlib provides the following tools to perform different types of operations.
ML Algorithms: It provides common learning algorithms such as classification, regression, clustering, and collaborative filtering.
Featurization: It provides feature extraction, transformation, dimensionality reduction, and selection.
Pipelines: It is used for creating, assessing, and tuning ML Pipelines.
Persistence: It provides saving and load algorithms, models, and Pipelines.
Utilities: These components are used for statistics, linear algebra, data handling, and so on.
5. GraphX
Apache Spark GraphX is a graph processing component of Spark architecture. GraphX is immutable as it is based on RDD. To perform graph operation, GraphX provides a different set of operators such as joinVertices, subgraph, and aggregateMessages also it provides Pregel API.
6. SparkR (R on Spark)
Apache SparkR is a distributed data structure implementation that supports operations like selection, filtering, aggregation, and so on. SparkR is the package of the R language. It also provides support for machine learning through the MLlib library.
RDD - Resilient Distributed Dataset
RDD stands for Resilient Distributed Dataset which is the main abstraction of Spark. RDD is a collection of elements that are partitioned across the nodes of the cluster and operated in parallel. RDD is automatically rebuilt upon failures and it can be persisted in memory. The basic operations performed on RDD are map, filters, and persist. RDD process data by using transformations and actions.
RDD Creation
There are the following two ways in which we can create RDD.
1. Parallelizing Collection
2. Referencing External Dataset
Now let us see how to create RDD.
1. Parallelizing Collection
- In this mode of RDD creation, we can call SparkContext’s parallelize method on an existing collection in the driver program.
- Now the collection is copied from the distributed dataset and operated in coincidence.
- Now let us see the example to create Parallelizing Collection to hold a number from 1 to 7.
2. Referencing External Dataset
- It is another kind of RDD creation in which Spark RDD can be created from any data source supported by Hadoop such as HDFS, local file system, Cassandra, Amazon S3, HBase, and so on.
- The supported files format for Apache Spark is SequenceFile, textfile, Hadoop InputFormat, and so on.
| Scala | |
|---|---|
| Java | |
| Python |
RDD Operations
Apache Spark supports the following two types of RDD operations.
1. Transformations
2. Actions
Let us understand both operations.
1. Transformations
- It is a set of operations that define how RDD would be transformed.
- A new data set can be created based on the existing data set.
- Example of Transformations are :- map(),filter(),flatMap() etc.
2. Actions
- Actions perform computation on the data set and return the result to the driver program.
- Example of Actions are:- reduce(), collect(),count(),first() etc.
Features of Apache Spark
There are many features of Apache Spark and a few of them are as below.
1. Speed
Apache Spark provides very optimum performance for batch processing as well as stream processing. It uses a state-of-the-art DAG scheduler, physical execution engine, and query optimizer to achieve this. It provides 100 times faster workload management compared to Hadoop.
2. In-Memory Computation
Apache spark can perform in-memory processing which increased the processing speed.
3. Fault Tolerance
Spark achieve fault tolerance through its core abstraction RDD, Even in case of failure in the worker node, the lost partition of RDD can be computed referring to the original one.
4. Real-Time Stream Processing
Apache spark can do real-time data processing which was not supported by Hadoop. Hadoop was able to process data that are already present in storage.
5. Multiple Languages
Apache Spark provides supports for multiple languages like Java, Python, R, and Scala.
6. Lazy Evaluation
All transformations in Spark are lazy which means they will not compute their results right away. The computation will take place only when an action is called.
7. Integrated with Hadoop YARN
Apache Spark can run independently and it can run on Hadoop YARN cluster manager as well.