Diagnostic operators are used to verifying the execution flow, displaying data on the terminal, checking logical and physical execution plans of MapReduce, and so on.
Pig provides the below list of Diagnostic Operators.
Let us see each Diagnostic operator in detail.
1. DUMP Operator
In Pig, the DUMP operator is used to projecting the result of Pig Latin on the terminal.
Syntax:
grunt> DUMP alias;
To perform the DUMP operation, first, we will load a file name “employee.txt” in HDFS “/pigexample/” location. The content of the file is mentioned below.
1001,James,Butt,New Orleans,Orleans
1002,Josephine,Darakjy,Brighton,Livingston
1003,Art,Venere,Bridgeport,Gloucester
1004,Lenna,Paprocki,Anchorage,Anchorage
1005,Donette,Foller,Hamilton,Butler
1006,Simona,Morasca,Ashland,Ashland
1007,Mitsue,Tollner,Chicago,Cook
1008,Leota,Dilliard,San Jose,Santa
1009,Sage,Wieser,Sioux Falls,Minnehaha
Command:
grunt> employees = LOAD '/pigexample/employee.txt' USING PigStorage(',') as (empid:int,firstname:chararray,lastname:chararray,city:chararray,county:chararray );
Once data is loaded in Pig, we will use the Dump operator to print the content of the “employee.txt” file.
Command:
grunt> DUMP employees;
A MapReduce job will start when we will submit the Dump command. It will read data from HDFS and show the below output.
Output:
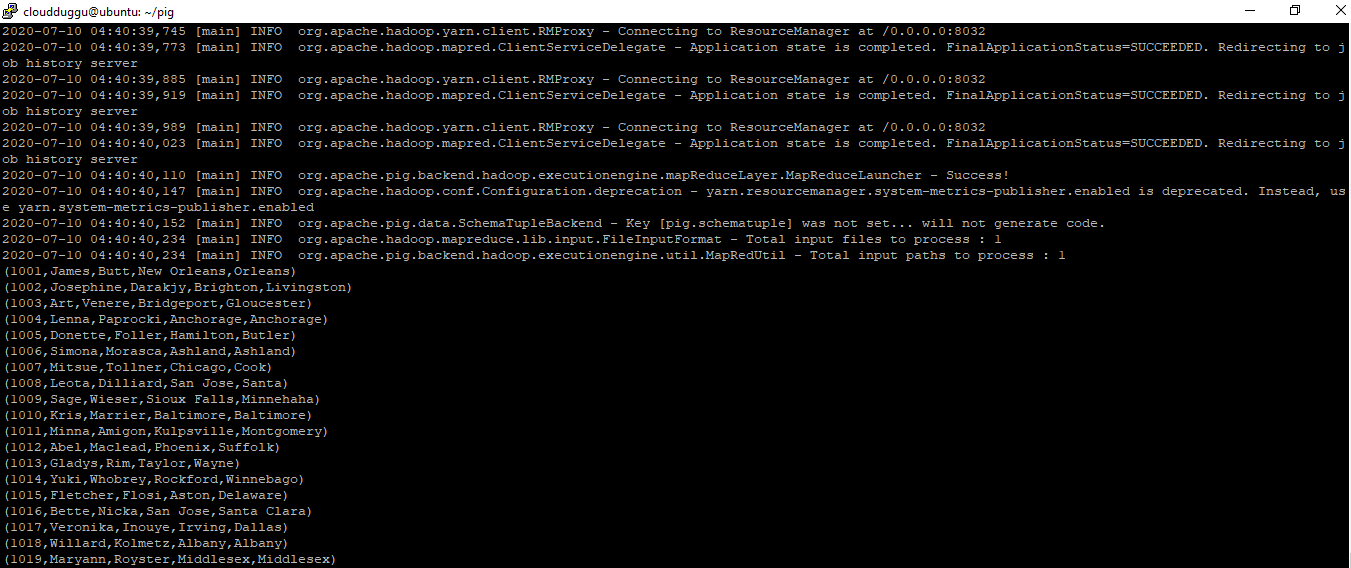
2. DESCRIBE Operator
DESCRIBE operator is used to viewing the structure of a schema.
Syntax:
grunt> DESCRIBE alias;
We will use DESCRIBE operator to see the structure of schema “employees” which was created in the DUMP section.
Command:
grunt> DESCRIBE employees;
Output:

3. EXPLAIN Operator
3. EXPLAIN Operator
EXPLAIN operator is used to reviewing the logical, physical, and MapReduce execution plans that are used to compute the specified relationship.
Syntax:
grunt> EXPLAIN alias;
We will use EXPLAIN operator to see the logical, physical, and MapReduce execution plans of schema “employees” which was created in the DUMP section.
Command:
grunt> EXPLAIN employees;
Output:
grunt> EXPLAIN employees;
2020-07-11 03:19:35,289 [main] INFO org.apache.pig.data.SchemaTupleBackend - Key [pig.schematuple] was
not set... will not generate code.
2020-07-11 03:19:35,446 [main] INFO org.apache.pig.newplan.logical.optimizer.LogicalPlanOptimizer -
{RULES_ENABLED=[AddForEach, ColumnMapKeyPrune, ConstantCalculator, GroupByConstParallelSetter,
LimitOptimizer, LoadTypeCastInserter, MergeFilter, MergeForEach, NestedLimitOptimizer,
PartitionFilterOptimizer, PredicatePushdownOptimizer, PushDownForEachFlatten, PushUpFilter, SplitFilter,
StreamTypeCastInserter]}
#-----------------------------------------------
# New Logical Plan:
#-----------------------------------------------
employees: (Name: LOStore Schema:
empid#11:int,firstname#12:chararray,lastname#13:chararray,city#14:chararray,county#15:chararray)
|
|---employees: (Name: LOForEach Schema:
empid#11:int,firstname#12:chararray,lastname#13:chararray,city#14:chararray,county#15:chararray)
| |
| (Name: LOGenerate[false,false,false,false,false] Schema:
empid#11:int,firstname#12:chararray,lastname#13:chararray,city#14:chararray,county#15:chararray)ColumnPrune:OutputUids=[11,
12, 13, 14, 15]ColumnPrune:InputUids=[11, 12, 13, 14, 15]
| | |
| | (Name: Cast Type: int Uid: 11)
| | |
| | |---empid:(Name: Project Type: bytearray Uid: 11 Input: 0 Column: (*))
| | |
| | (Name: Cast Type: chararray Uid: 12)
| | |
| | |---firstname:(Name: Project Type: bytearray Uid: 12 Input: 1 Column: (*))
| | |
| | (Name: Cast Type: chararray Uid: 13)
| | |
| | |---lastname:(Name: Project Type: bytearray Uid: 13 Input: 2 Column: (*))
| | |
| | (Name: Cast Type: chararray Uid: 14)
| | |
| | |---city:(Name: Project Type: bytearray Uid: 14 Input: 3 Column: (*))
| | |
| | (Name: Cast Type: chararray Uid: 15)
| | |
| | |---county:(Name: Project Type: bytearray Uid: 15 Input: 4 Column: (*))
| |
| |---(Name: LOInnerLoad[0] Schema: empid#11:bytearray)
| |
| |---(Name: LOInnerLoad[1] Schema: firstname#12:bytearray)
| |
| |---(Name: LOInnerLoad[2] Schema: lastname#13:bytearray)
| |
| |---(Name: LOInnerLoad[3] Schema: city#14:bytearray)
| |
| |---(Name: LOInnerLoad[4] Schema: county#15:bytearray)
|
|---employees: (Name: LOLoad Schema:
empid#11:bytearray,firstname#12:bytearray,lastname#13:bytearray,city#14:bytearray,county#15:bytearray)RequiredFields:null
2020-07-11 03:19:35,804 [main] INFO org.apache.pig.impl.util.SpillableMemoryManager - Selected heap
(Tenured Gen) of size 699072512 to monitor. collectionUsageThreshold = 489350752, usageThreshold =
489350752
#-----------------------------------------------
# Physical Plan:
#-----------------------------------------------
employees: Store(fakefile:org.apache.pig.builtin.PigStorage) - scope-17
|
|---employees: New For Each(false,false,false,false,false)[bag] - scope-16
| |
| Cast[int] - scope-2
| |
| |---Project[bytearray][0] - scope-1
| |
| Cast[chararray] - scope-5
| |
| |---Project[bytearray][1] - scope-4
| |
| Cast[chararray] - scope-8
| |
| |---Project[bytearray][2] - scope-7
| |
| Cast[chararray] - scope-11
| |
| |---Project[bytearray][3] - scope-10
| |
| Cast[chararray] - scope-14
| |
| |---Project[bytearray][4] - scope-13
|
|---employees: Load(/pigexample/employee.txt:PigStorage(',')) - scope-0
2020-07-11 03:19:36,167 [main] INFO
org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MRCompiler - File concatenation threshold:
100 optimistic? false
2020-07-11 03:19:36,298 [main] INFO
org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MultiQueryOptimizer - MR plan size before
optimization: 1
2020-07-11 03:19:36,299 [main] INFO
org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MultiQueryOptimizer - MR plan size after
optimization: 1
#--------------------------------------------------
# Map Reduce Plan
#--------------------------------------------------
MapReduce node scope-18
Map Plan
employees: Store(fakefile:org.apache.pig.builtin.PigStorage) - scope-17
|
|---employees: New For Each(false,false,false,false,false)[bag] - scope-16
| |
| Cast[int] - scope-2
| |
| |---Project[bytearray][0] - scope-1
| |
| Cast[chararray] - scope-5
| |
| |---Project[bytearray][1] - scope-4
| |
| Cast[chararray] - scope-8
| |
| |---Project[bytearray][2] - scope-7
| |
| Cast[chararray] - scope-11
| |
| |---Project[bytearray][3] - scope-10
| |
| Cast[chararray] - scope-14
| |
| |---Project[bytearray][4] - scope-13
|
|---employees: Load(/pigexample/employee.txt:PigStorage(',')) - scope-0--------
Global sort: false
----------------
4. ILLUSTRATE Operator
grunt> EXPLAIN employees;
2020-07-11 03:19:35,289 [main] INFO org.apache.pig.data.SchemaTupleBackend - Key [pig.schematuple] was
not set... will not generate code.
2020-07-11 03:19:35,446 [main] INFO org.apache.pig.newplan.logical.optimizer.LogicalPlanOptimizer -
{RULES_ENABLED=[AddForEach, ColumnMapKeyPrune, ConstantCalculator, GroupByConstParallelSetter,
LimitOptimizer, LoadTypeCastInserter, MergeFilter, MergeForEach, NestedLimitOptimizer,
PartitionFilterOptimizer, PredicatePushdownOptimizer, PushDownForEachFlatten, PushUpFilter, SplitFilter,
StreamTypeCastInserter]}
#-----------------------------------------------
# New Logical Plan:
#-----------------------------------------------
employees: (Name: LOStore Schema:
empid#11:int,firstname#12:chararray,lastname#13:chararray,city#14:chararray,county#15:chararray)
|
|---employees: (Name: LOForEach Schema:
empid#11:int,firstname#12:chararray,lastname#13:chararray,city#14:chararray,county#15:chararray)
| |
| (Name: LOGenerate[false,false,false,false,false] Schema:
empid#11:int,firstname#12:chararray,lastname#13:chararray,city#14:chararray,county#15:chararray)ColumnPrune:OutputUids=[11,
12, 13, 14, 15]ColumnPrune:InputUids=[11, 12, 13, 14, 15]
| | |
| | (Name: Cast Type: int Uid: 11)
| | |
| | |---empid:(Name: Project Type: bytearray Uid: 11 Input: 0 Column: (*))
| | |
| | (Name: Cast Type: chararray Uid: 12)
| | |
| | |---firstname:(Name: Project Type: bytearray Uid: 12 Input: 1 Column: (*))
| | |
| | (Name: Cast Type: chararray Uid: 13)
| | |
| | |---lastname:(Name: Project Type: bytearray Uid: 13 Input: 2 Column: (*))
| | |
| | (Name: Cast Type: chararray Uid: 14)
| | |
| | |---city:(Name: Project Type: bytearray Uid: 14 Input: 3 Column: (*))
| | |
| | (Name: Cast Type: chararray Uid: 15)
| | |
| | |---county:(Name: Project Type: bytearray Uid: 15 Input: 4 Column: (*))
| |
| |---(Name: LOInnerLoad[0] Schema: empid#11:bytearray)
| |
| |---(Name: LOInnerLoad[1] Schema: firstname#12:bytearray)
| |
| |---(Name: LOInnerLoad[2] Schema: lastname#13:bytearray)
| |
| |---(Name: LOInnerLoad[3] Schema: city#14:bytearray)
| |
| |---(Name: LOInnerLoad[4] Schema: county#15:bytearray)
|
|---employees: (Name: LOLoad Schema:
empid#11:bytearray,firstname#12:bytearray,lastname#13:bytearray,city#14:bytearray,county#15:bytearray)RequiredFields:null
2020-07-11 03:19:35,804 [main] INFO org.apache.pig.impl.util.SpillableMemoryManager - Selected heap
(Tenured Gen) of size 699072512 to monitor. collectionUsageThreshold = 489350752, usageThreshold =
489350752
#-----------------------------------------------
# Physical Plan:
#-----------------------------------------------
employees: Store(fakefile:org.apache.pig.builtin.PigStorage) - scope-17
|
|---employees: New For Each(false,false,false,false,false)[bag] - scope-16
| |
| Cast[int] - scope-2
| |
| |---Project[bytearray][0] - scope-1
| |
| Cast[chararray] - scope-5
| |
| |---Project[bytearray][1] - scope-4
| |
| Cast[chararray] - scope-8
| |
| |---Project[bytearray][2] - scope-7
| |
| Cast[chararray] - scope-11
| |
| |---Project[bytearray][3] - scope-10
| |
| Cast[chararray] - scope-14
| |
| |---Project[bytearray][4] - scope-13
|
|---employees: Load(/pigexample/employee.txt:PigStorage(',')) - scope-0
2020-07-11 03:19:36,167 [main] INFO
org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MRCompiler - File concatenation threshold:
100 optimistic? false
2020-07-11 03:19:36,298 [main] INFO
org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MultiQueryOptimizer - MR plan size before
optimization: 1
2020-07-11 03:19:36,299 [main] INFO
org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MultiQueryOptimizer - MR plan size after
optimization: 1
#--------------------------------------------------
# Map Reduce Plan
#--------------------------------------------------
MapReduce node scope-18
Map Plan
employees: Store(fakefile:org.apache.pig.builtin.PigStorage) - scope-17
|
|---employees: New For Each(false,false,false,false,false)[bag] - scope-16
| |
| Cast[int] - scope-2
| |
| |---Project[bytearray][0] - scope-1
| |
| Cast[chararray] - scope-5
| |
| |---Project[bytearray][1] - scope-4
| |
| Cast[chararray] - scope-8
| |
| |---Project[bytearray][2] - scope-7
| |
| Cast[chararray] - scope-11
| |
| |---Project[bytearray][3] - scope-10
| |
| Cast[chararray] - scope-14
| |
| |---Project[bytearray][4] - scope-13
|
|---employees: Load(/pigexample/employee.txt:PigStorage(',')) - scope-0--------
Global sort: false
----------------
4. ILLUSTRATE Operator
ILLUSTRATE operator is used to displaying step-by-step execution of a sequence of Pig Latin statements.
Syntax:
grunt> ILLUSTRATE alias;
We will use ILLUSTRATE operator to see the step-by-step execution of a sequence of schema “employees” which was created in the DUMP section.
Command:
grunt> ILLUSTRATE employees;
Output:
The following output is shown if we use ILLUSTRATE employees command.
2020-07-11 03:28:11,993 [main] INFO org.apache.pig.impl.util.SpillableMemoryManager - Selected heap
(Tenured Gen) of size 699072512 to monitor. collectionUsageThreshold = 489350752, usageThreshold =
489350752
2020-07-11 03:28:11,994 [main] WARN org.apache.pig.data.SchemaTupleBackend - SchemaTupleBackend has
already been initialized
2020-07-11 03:28:11,995 [main] INFO
org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.PigMapOnly$Map - Aliases being processed
per job phase (AliasName[line,offset]): M: employees[1,12] C: R:
---------------------------------------------------------------------------------------------------------------------------
| employees | empid:int | firstname:chararray | lastname:chararray | city:chararray | county:chararray |
---------------------------------------------------------------------------------------------------------------------------
| | 1008 | Leota | Dilliard | San Jose | Santa |
---------------------------------------------------------------------------------------------------------------------------
Again if we run “ILLUSTRATE employees;” we get another output because it is displaying execution step by step.
2020-07-11 03:28:19,644 [main] INFO org.apache.pig.impl.util.SpillableMemoryManager - Selected heap
(Tenured Gen) of size 699072512 to monitor. collectionUsageThreshold = 489350752, usageThreshold =
489350752
2020-07-11 03:28:19,655 [main] WARN org.apache.pig.data.SchemaTupleBackend - SchemaTupleBackend has
already been initialized
2020-07-11 03:28:19,656 [main] INFO
org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.PigMapOnly$Map - Aliases being processed
per job phase (AliasName[line,offset]): M: employees[1,12] C: R:
---------------------------------------------------------------------------------------------------------------------------
| employees | empid:int | firstname:chararray | lastname:chararray | city:chararray | county:chararray |
---------------------------------------------------------------------------------------------------------------------------
| | 1014 | Yuki | Whobrey | Rockford | Winnebago |
---------------------------------------------------------------------------------------------------------------------------