Apache Pig Grunt is an interactive shell that enables users to enter Pig Latin interactively and provides a shell to interact with HDFS and local file system commands. You can enter Pig Latin commands directly into the Grunt shell for execution. Apache Pig starts executing the Pig Latin language when it receives the STORE or DUMP command. Before executing the command Pig Grunt shell do check the syntax and semantics to void any error.
To start Pig Grunt type :
$pig -x localIt will start Pig Grunt shell:
grunt>Now using Grunt shell you can interact with your local filesystem. But if you forget the -x local and have a cluster configuration set in PIG_CLASSPATH, then it put you in a Grunt shell that will interact with HDFS on your cluster.
HDFS commands in Pig Grunt
We can use the Pig Grunt shell to run HDFS commands as well. Starting from Pig version 0.5 all Hadoop fs shell commands are available to use. They are accessed using the keyword FS followed by the command.
Let us see few HDFS commands from the Pig Grunt shell.
fs -ls /
This command will print all directories present in HDFS “/”.
Syntax:
grunt> fs subcommand subcommand_parameters;
Command:
grunt> fs -ls /
Output:

fs -cat
Output:
fs -cat
This command will print the content of a file present in HDFS.
Syntax:
grunt> fs subcommand subcommand_parameters
Command:
grunt> fs -cat /hive/warehouse/kv2.txt
Output:

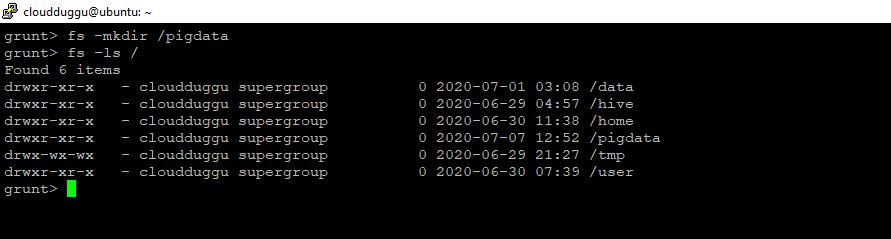
fs -mkdir
Output:
fs -mkdir
This command will create a directory in HDFS.
Syntax:
grunt> fs subcommand subcommand_parameters
Command:
grunt> fs -mkdir /pigdata
Output:
fs -copyFromLocal
Output:
fs -copyFromLocal
This command will copy a file from the local system to HDFS.
Syntax:
grunt> fs subcommand subcommand_parameters
Command:
grunt> fs -copyFromLocal /home/cloudduggu/pig/tutorial/emp.txt /pigdata/
Output:

Shell commands in Pig Grunt
Output:
Shell commands in Pig Grunt
We can use the Pig Grunt shell to run the basic shell command. We can invoke any shell commands using sh.
Let us see few Shell commands from the Pig Grunt shell. We cannot execute those commands which are part of the shell environment such as –cd.
sh ls
This command will list all directories/files.
Syntax:
grunt> sh subcommand subcommand_parameters
Command:
grunt> sh ls
Output:

sh cat
Output:
sh cat
This command will print the content of a file.
Syntax:
grunt> sh subcommand subcommand_parameters
Command:
grunt> sh cat
Output:

Utility commands in Pig Grunt
Output:
Utility commands in Pig Grunt
Pig Grunt supports utilities commands as well such as help, clear, history apart from this Grunt also provides commands for controlling Pig and MapReduce such as exec, run, kill.
Help Command
Help command provides a list of Pig commands.
Syntax:
grunt> help
Command:
grunt> help
Output:

Clear Command
Output:
Clear Command
Clear command is used to clear the screen of the Grunt shell.
Syntax:
grunt> Clear
Command:
grunt> Clear
History Command
History Command
The history command is used to clear the screen of the Grunt shell.
Syntax:
grunt> history
Command:
grunt> history
Output:

Set Command
Output:
Set Command
The SET command is used to assign values to keys that are case sensitive. In case the SET command is used without providing arguments then all other system properties and configurations are printed.
Syntax:
grunt> set [key 'value']
Command:
grunt> SET debug 'on'
grunt> SET job.name 'my job'
grunt> SET default_parallel 100
grunt> SET job.name 'my job'
grunt> SET default_parallel 100
| Key | Description | default_parallel | Using this parameter you can set the number of reducers for all MapReduce jobs generated by Pig. | debug | Using this parameter you can turn debug-level logging on or off. | job.name | Using this parameter you can set a user-specified name for the job. | job.priority | Using this parameter you can set the priority of a Pig job such as very_low, low, normal, high, very_high. | stream.skippath | Using this parameter you can set the path from where the data is not to be transferred, bypassing the desired path in the form of a string to this key. |
|---|
EXEC Command
Exec command is used to execute Pig script from Grunt shell.
Please make sure the history server is running. You can verify in the JPS command output. This service “JobHistoryServer” should be running otherwise you can start it using the below command.
$ /home/cloudduggu/hadoop/sbin$./mr-jobhistory-daemon.sh start historyserverLet us assume that we have a file name “emp.txt” which is present on HDFS /pigdata/ directory. Now we want to use this file and project its content using Pig script.
Content of “emp.txt”:
201,Wick,Google
203,John,Facebook
204,Partick,Instagram
205,Hema,Google
206,Holi,Facebook
207,Michael,Instagram
208,Michael,Instagram
209,Chung,Instagram
210,Anna,Instagram
201,Wick,Google
203,John,Facebook
204,Partick,Instagram
205,Hema,Google
206,Holi,Facebook
207,Michael,Instagram
208,Michael,Instagram
209,Chung,Instagram
210,Anna,Instagram
Now we will create an “emp_script.pig” script file which will have the below statements to process data and put this file on the same location of HDFS that is /pigdata/.
Content of “emp_script.pig”:
employee = LOAD 'hdfs://localhost:9000/pigdata/emp.txt' USING PigStorage(',')
as (empid:int,empname:chararray,salary:int);
dump employee;
employee = LOAD 'hdfs://localhost:9000/pigdata/emp.txt' USING PigStorage(',')
as (empid:int,empname:chararray,salary:int);
dump employee;
Now we will start the Pig Grunt shell and run the script.
Syntax:
grunt> exec [–param param_name = param_value] [–param_file file_name] [script]
Command:
$pig
grunt> exec hdfs:///pigdata/emp_script.pigOutput:


Kill Command
The kill command will attempt to kill any MapReduce jobs associated with the Pig job
Syntax:
grunt> kill JobId
Command:
grunt> kill job_500
Run Command
Run Command
The run command is used to run a Pig script that can interact with the Grunt shell (interactive mode).
The difference between the “exec” and “run” command is that in the run command you can see commands output on screen but in “exec” it is not.
We will use the same example which we used for “exec command” and run the below command.

